Tektur - real-time CCMS
DITA Publishing + Review & Approval
Tektur CMS is a lightweight, web-based Component Content Management System (CCMS) designed forsmall teams and freelance authors who need to deliver structured content in DITA format.
Unlike traditional desktop CCMS tools, Tektur CMS runs entirely in the browser, offering a seamless, real-time editing experience with an intuitive, Word-like XML editor. Authors can easily create, manage, and reuse thousands of topics - and import or export content in standard ZIP packages.
With its open API and modular architecture, Tektur CMS integrates smoothly into larger enterprise environments while remaining affordable, flexible, and ready for the future of AI-assisted content creation.
This is the development blog maintained by Alex Düsel [ Work history / Profile ].

November 21st, 2025
AI Chat Integration
We've integrated an AI chat feature (experimental) into Tektur CCMS, making it easy to get assistance while working with your content.
See how it was developed in the video below.
November 5th, 2025
Tektur CCMS Demo Version Available
A demo version of Tektur CCMS is now available for download. Installation is incredibly simple: You only need Docker Desktop, and the system is up and running in less than 5 minutes. The demo version can be downloaded at https://www.stylesheet-entwicklung.de/publiziere/#/tektur/download.
(Note: The video is not in 16:9 format, which causes some playback issues. I will create a new version of the video soon.)
September 7th, 2025
CSS Redesign with Claude Code
From now on, I'll be using AI tools to support my coding - and it's a game changer. Productivity easily increases by a factor of five. For example, I recently asked an AI assistant to redesign the CSS for this project, and within just ten minutes it delivered a complete dark theme that worked almost perfectly right out of the box. Here are a few screenshots:
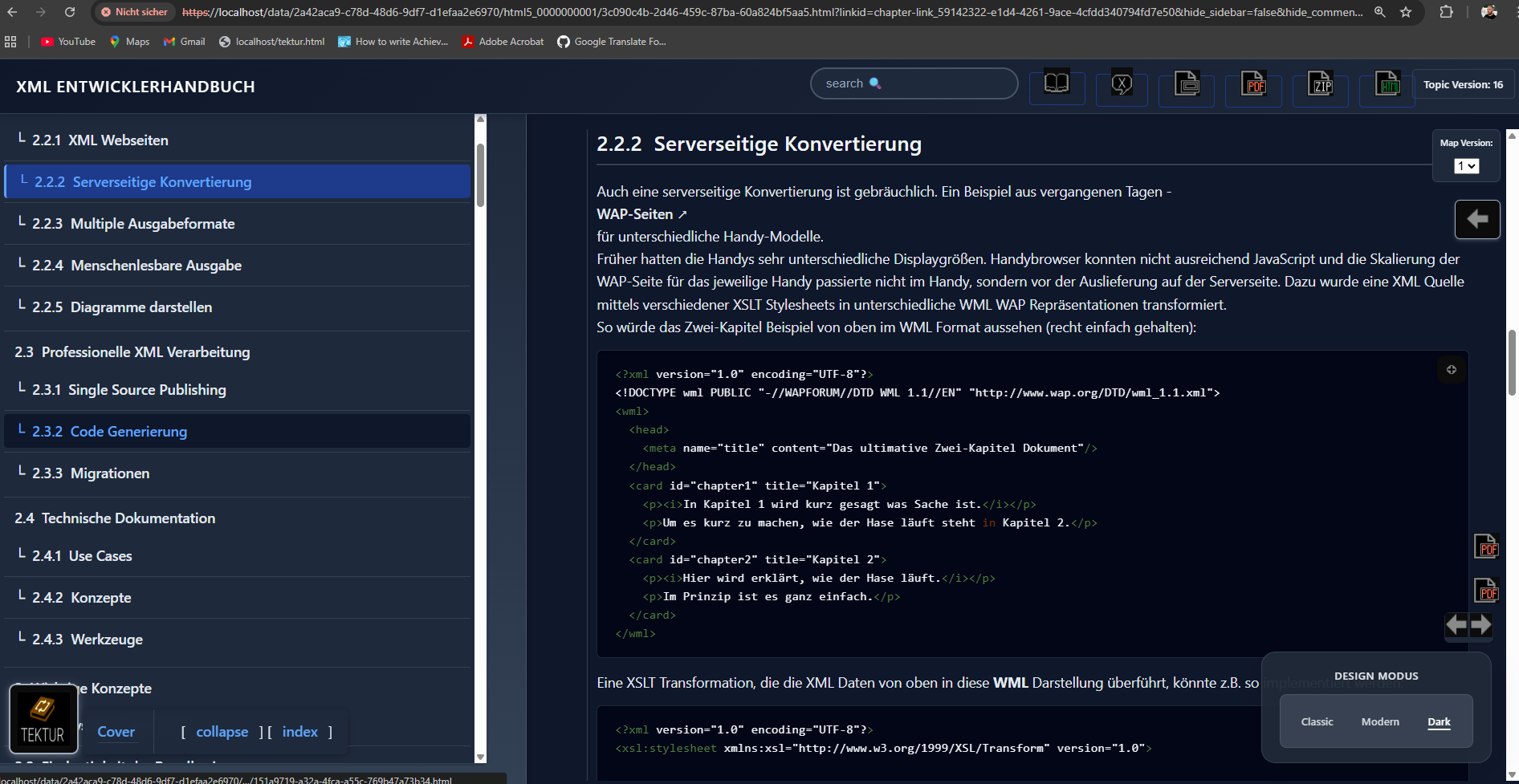
Older blog post without AI-assisted writing are below. Enjoy :-]
January 20th, 2025
Tektur CCMS Marketing Homepage
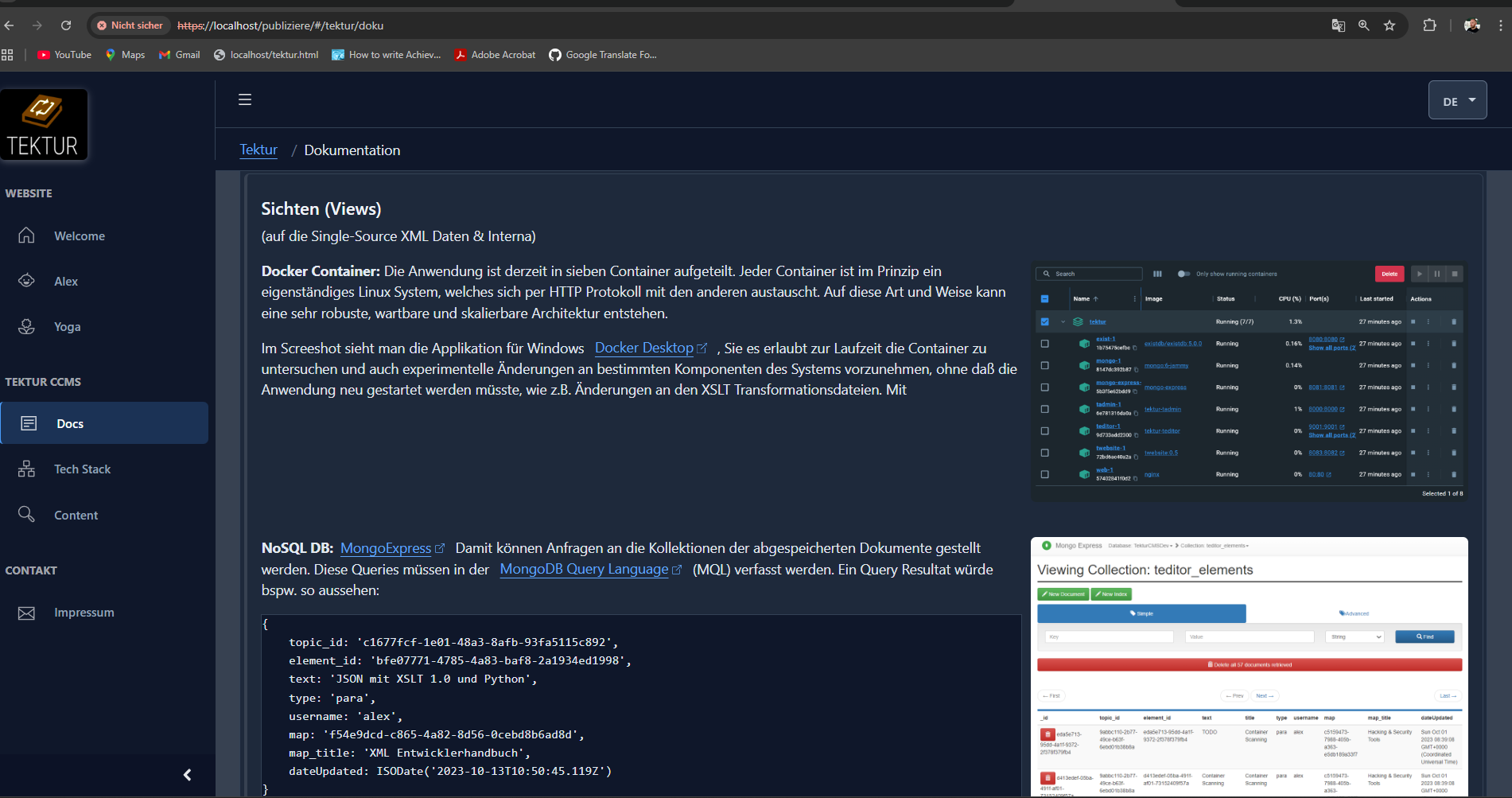
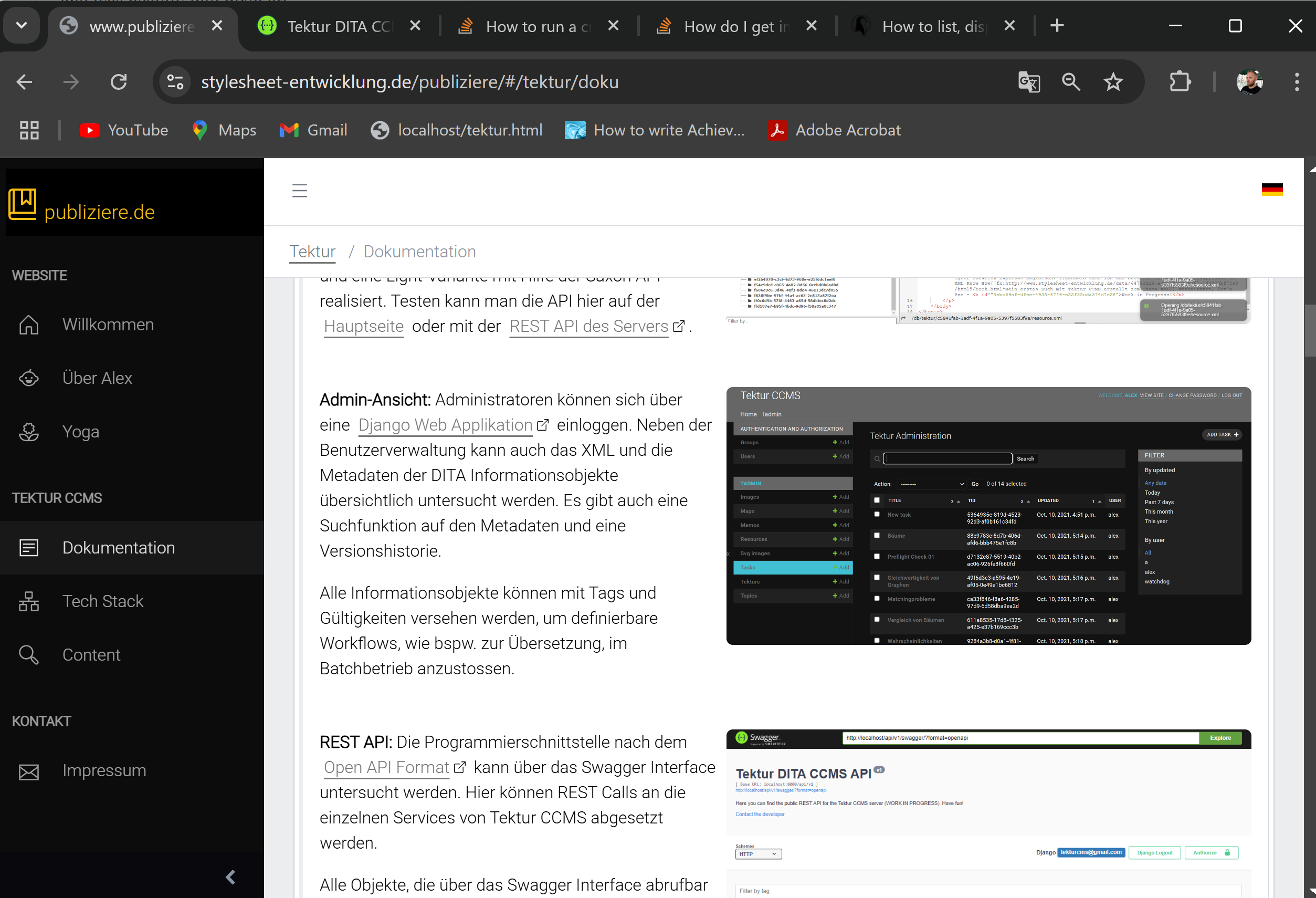
Just finished creating a fancy homepage (german speaking) for Tektur CCMS using a VueJS3 Single Page App that talks to the Tektur CCMS server via a REST API.
Visit the site www.publiziere.de.
The test server is also back online www.stylesheet-entwicklung.de.
December 6th, 2023
Shutdown Testserver & Tektur CCMS status
I used to run a dedicated server (with different OS and versions over the time) at Hosteurope for a couple of years. Due to the rising prices I quit the contract and bought a gaming PC instead.
It's so much fun to see the XSLT transformation speed at my local Tektur CCMS server! But unfortunately there is no public test server any more. So I put a couple of videos on Youtube (german language) just to document all the features that have been included during the last two years.
Admin interface and REST API:
Review & Approval Workflow
CCMS functions, output formats & M$ Word import
Finally here is a diagram about the general architecture. Don't hesitate to contact me if you have any queries about Tektur CCMS. I will put development on hold for a while.
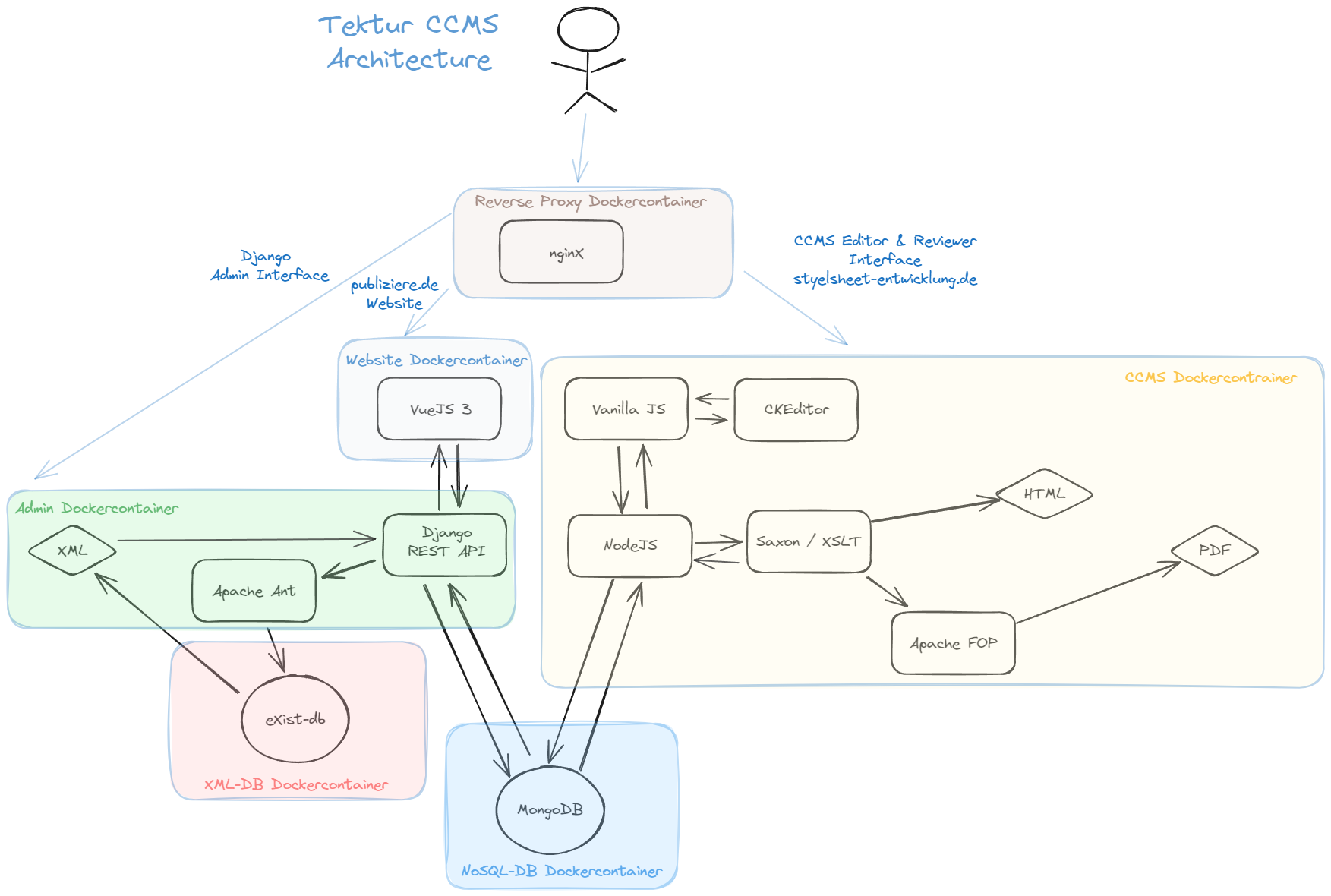
As you can see the application is fully containerized. There are currently six containes that share data in two volumes. There is a XML DB and a NoSQL DB backend and a fancy VueJS3 frontend that loads all data via the Tektur CCMS REST API
November 30th, 2022
Long time no see!
Good news: Tektur CCMS is still under development. I am currently working on some tricky and unique features, e.g. send an XPATH query via a REST API to a NoSQL database (MongoDB). This is actually impossible, since XPath should work with an XML database only.
With enough passion, courage and imagination it can be done quite easily. Steps including but no limited to:
- Decompose the XPath Query into tokens: Element names, attribute names and (PCDATA) values. You may apply some rules, like: "A word-like string followed by an opening round bracket always marks a function call which can be removed".
- Sort the tokens according to some heuristics, like "A hex value enclosed by quotes is likely to be a unique identifier and should be treated with priority".
- Create a performant regex query using the tokens. May be do not use all tokens if the reqex is clear. Search for: <elemname, @attributename, >PCDATA, ="attributevalue".
- Query the NoSQL database with the regex in order to retrieve some candidates for our original query. But there is a another pitfall because NoSQL does not support Regex.
- Run an XSLT stylesheet on each candidate with the original XPath Query.
- Return the list of extracted XML fragments to the REST API caller.
After some tests this procedure seems to be quite fast (if the heuristic is smart enough).
October 12th, 2019
Comment navigation and attachments
Improved the discussion functionality. There is a paper clip icon now...
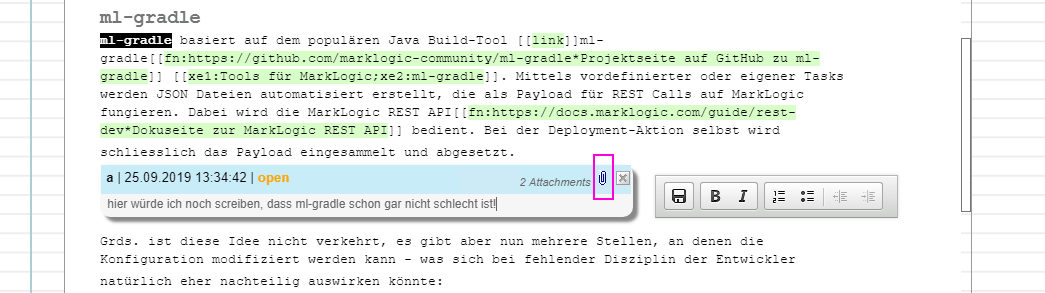
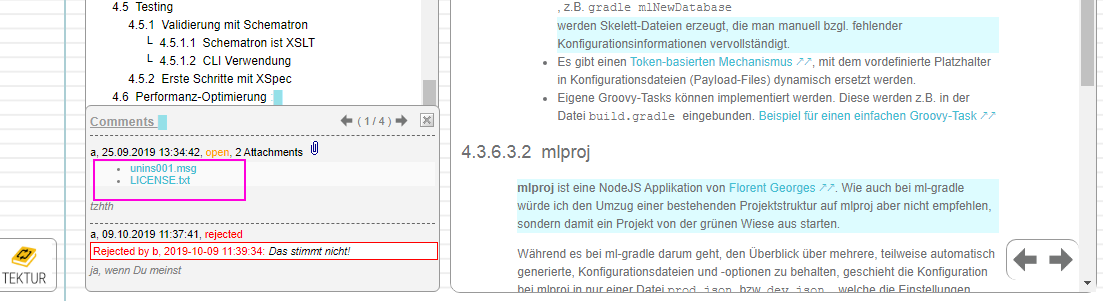
You can open the Attachments dialog by clicking on that paper clip...
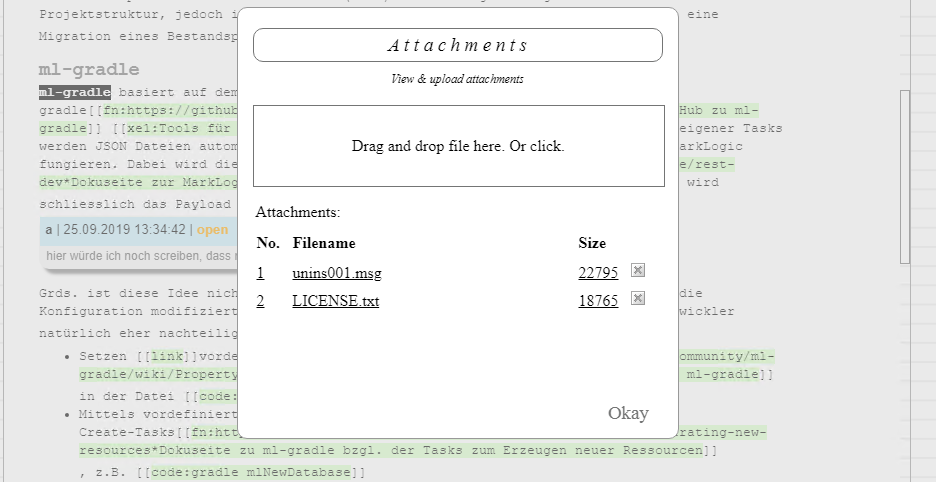
An approver may change the state of a comment and disable attachment upload...
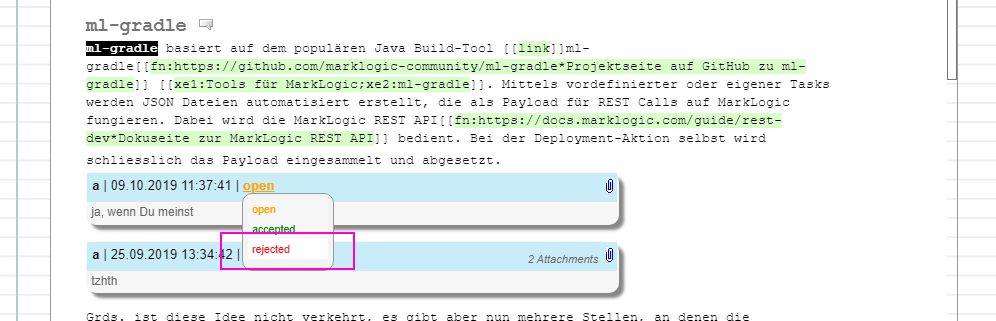
You need to reason about the rejection...
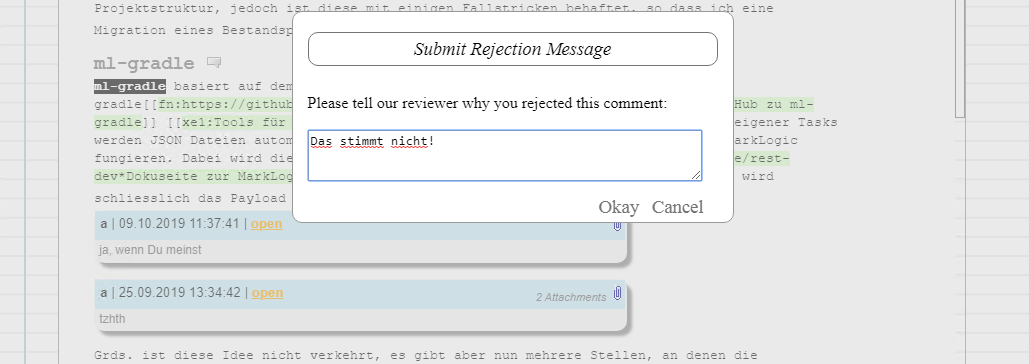
A reader may look at the comments...
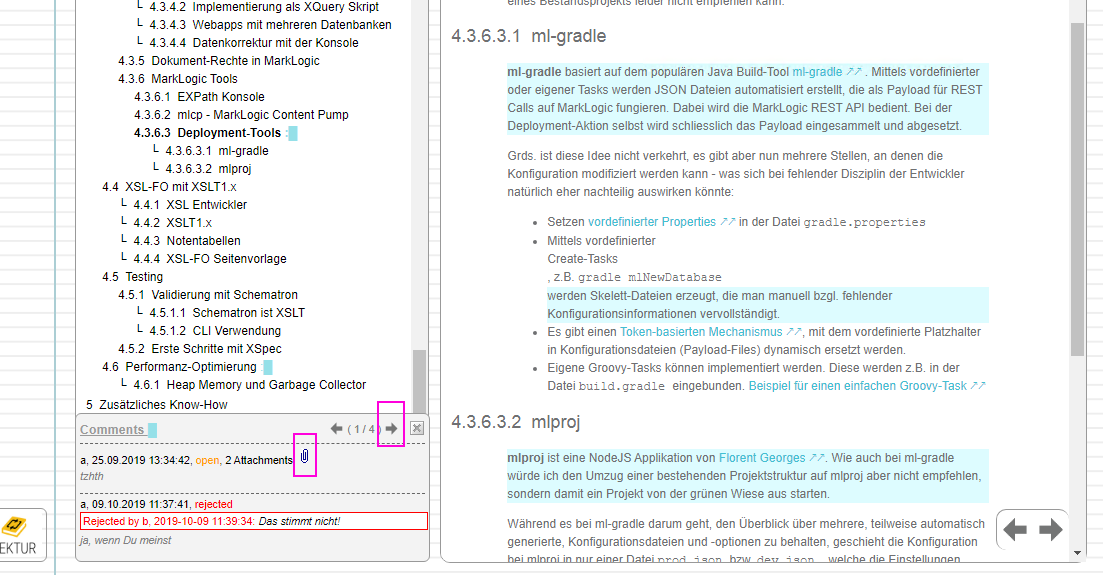
When hovering over a comment the discussion panel will show up - pin it with a click. Also, showing arrows for jumping from one comment to the next going through the entire publication.
August 18th, 2019
Frontpage
Added a simple frontpage to the system that lists all publications on the server. Also, latest changes and latest comments are listed.

July 14th, 2019
Simple HTML format
My friend George has come up with the idea that it would be really nice if you could just download a set of plain HTML pages which make up the book. Put this package on any webserver or even on the filesystem and voila, your work is published.
As far as I know none of the popular CMS systems, blog engines or wikis can do this. See how it works:
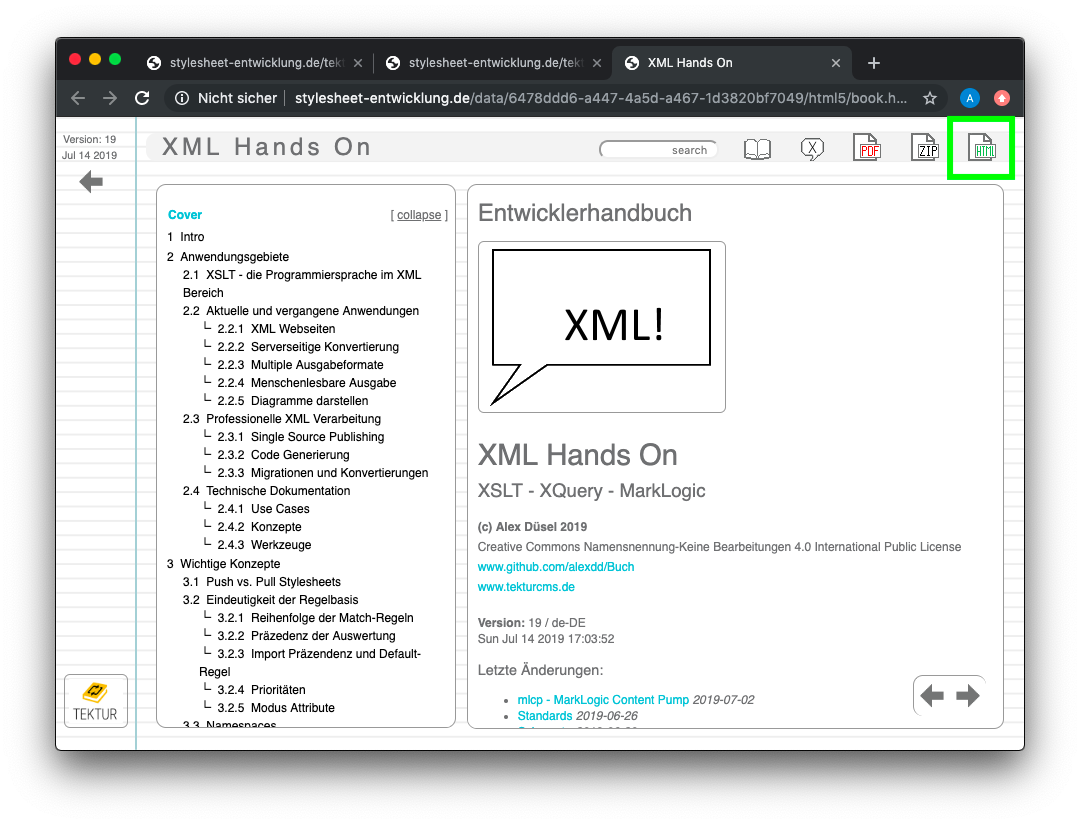
There's a new button on the Reader's view. Click it to download a ZIP containing HTML pages, images and an old school HTML frameset.
The design looks rather simple but it can be easily customised to meet your individual needs. The content is semantically well-tagged and there is just one CSS file.
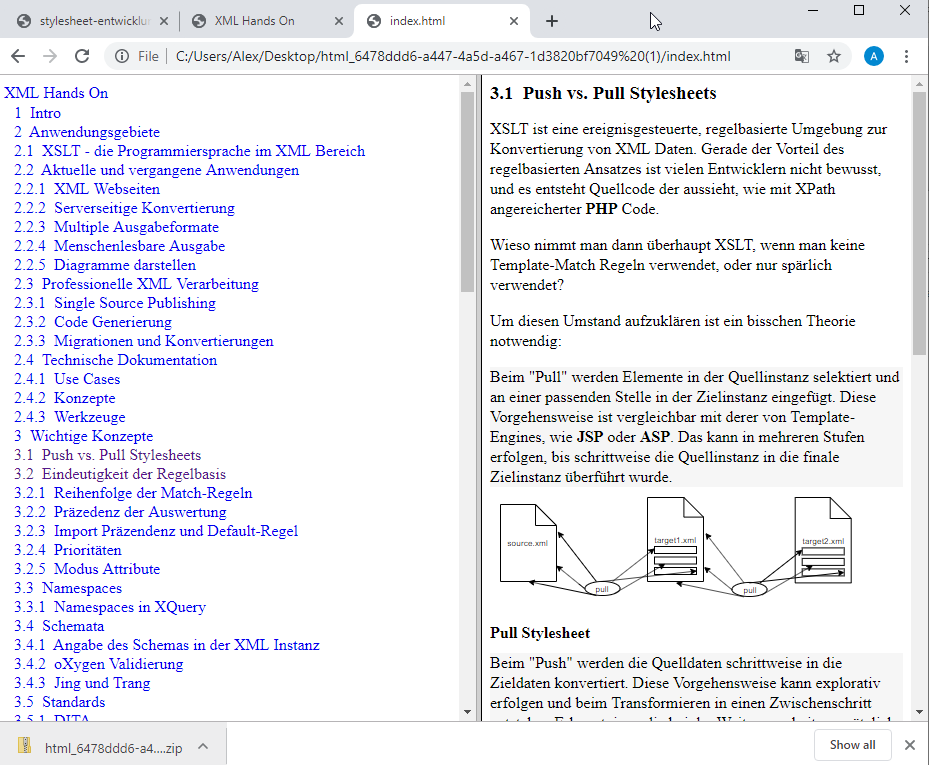
I used a HTML frameset for separating the TOC from the content. While this may not be the most elegant solution, it is at least widespread.
May 26th, 2019
Markdown Importer
Just finished the Markdown Importer. It works either on a document- / chapter-level but also on a paragraph-level. Some screenshots:
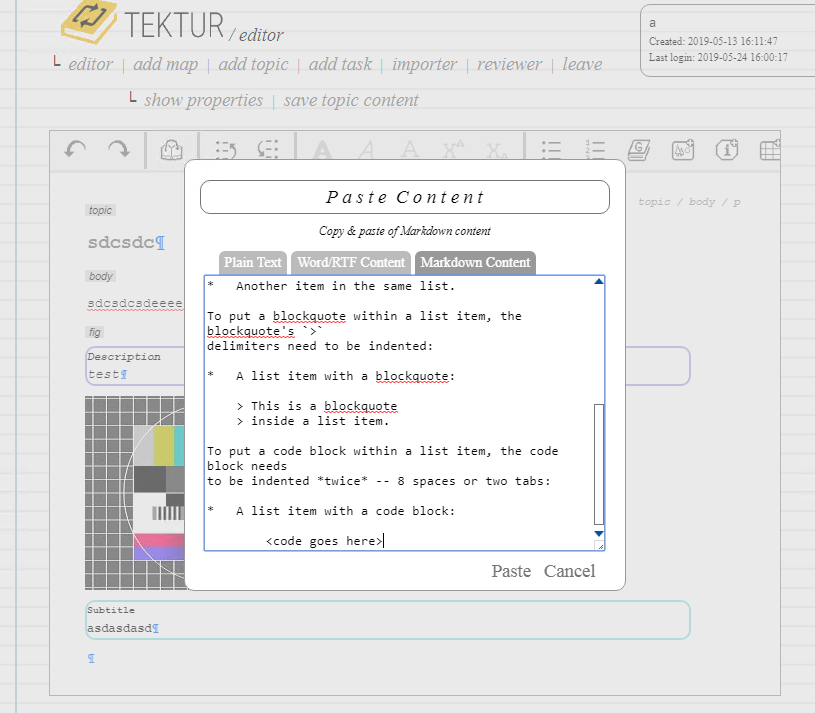
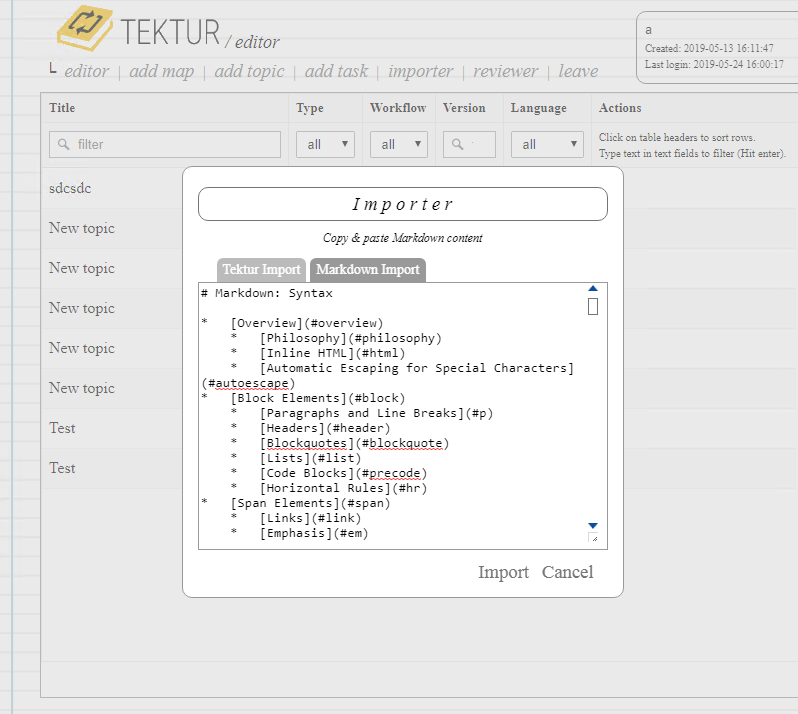
The implementation is pretty straight-forward and summed up below:
-
Convert Markdown to HTML using showdown.js.
-
Transform HTML to DITA XML using XSLT.
-
Flatten nested chapters (h3 to h6) in order to reflect the DITA topic vs. section hierachy.
-
Pick up result and import.
I tried it on the test file of John Gruber (who is one of the inventors of the Markdown syntax). The result looks quite nice in the editor:
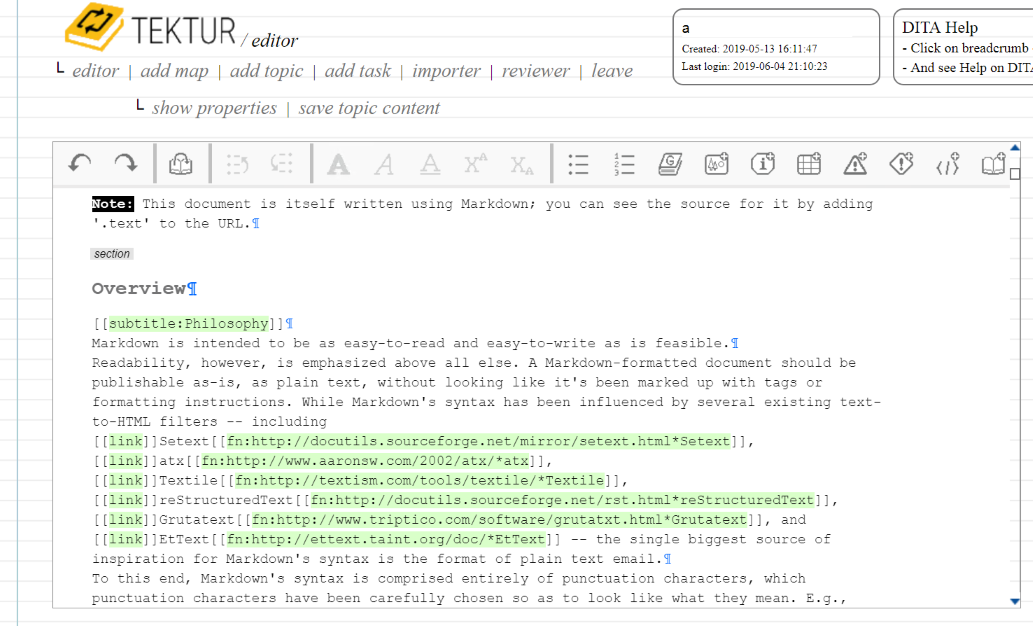
So why do we need a Markdown Importer here? It happens to be that most programmers use Markdown for documenting their projects for example on GitHub.. With this feature, Tektur allows software developers to contribute to a "master" document that may be assembled in a "post-authoring" workflow step, ready to be published as a PDF or any other format ...
April 19th, 2019
?? Fulltext-Search
Implemented full-text search! Normally I would use Apache Solr as a search engine but this time I gave the text index of MongoDB a chance in order to keep the stack easy and clean. The whole application is written in JavaScript/NodeJS and XSLT with MongoDB as database and Apache FOP as XSL-FO formatter. That's all. I am quite happy with this architectural decision:
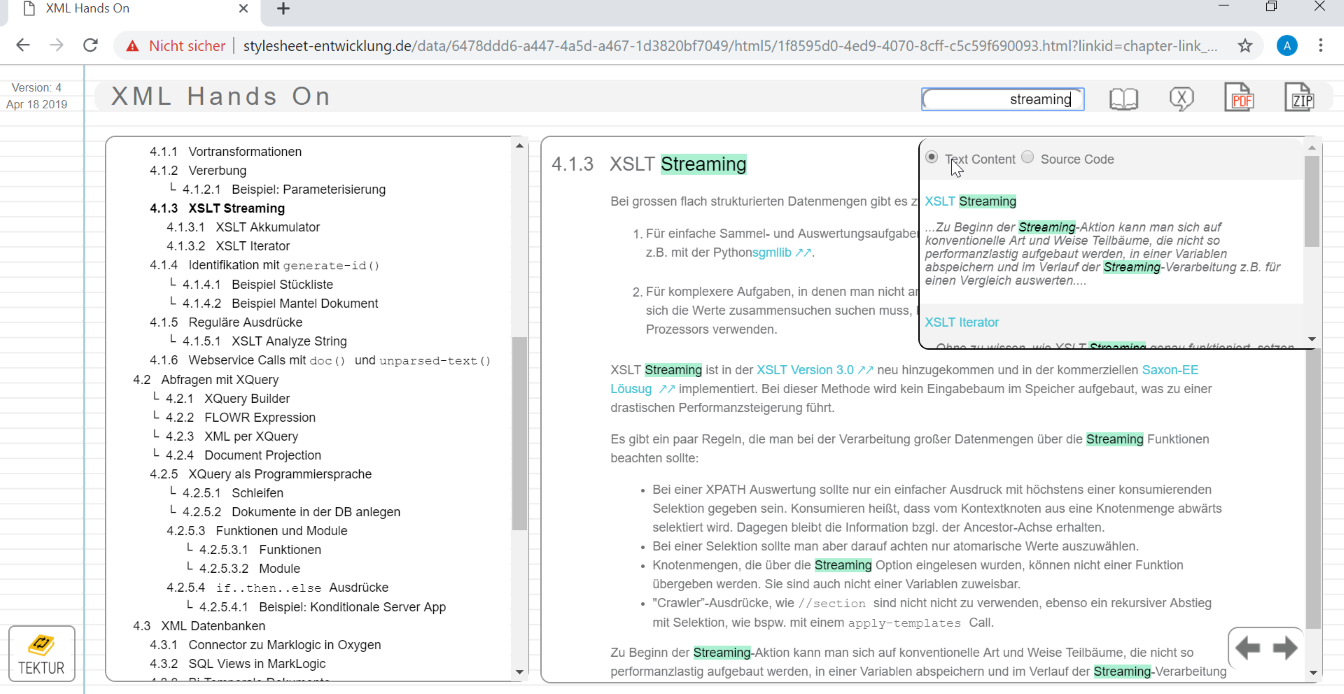
I am thinking about including more options like searching over certain elements. It does already work for source code snippets:
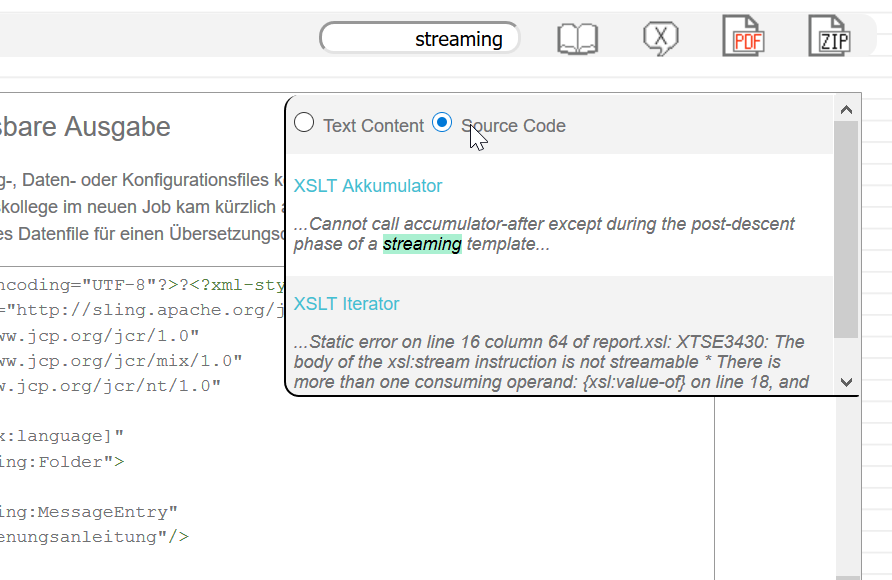
March 31st, 2019
Lazy-Tags & minor HTML improvments
Inroducing "Lazy-Tags" ... At some point we are just to lazy to extend the DITA model, add some new icons to the editor toolbar, customize the XSLT templates and CSS if we just want to include some simple markup tags that will only have some technical functionality and no semantic meaning. This is why I invented lazy-tags:
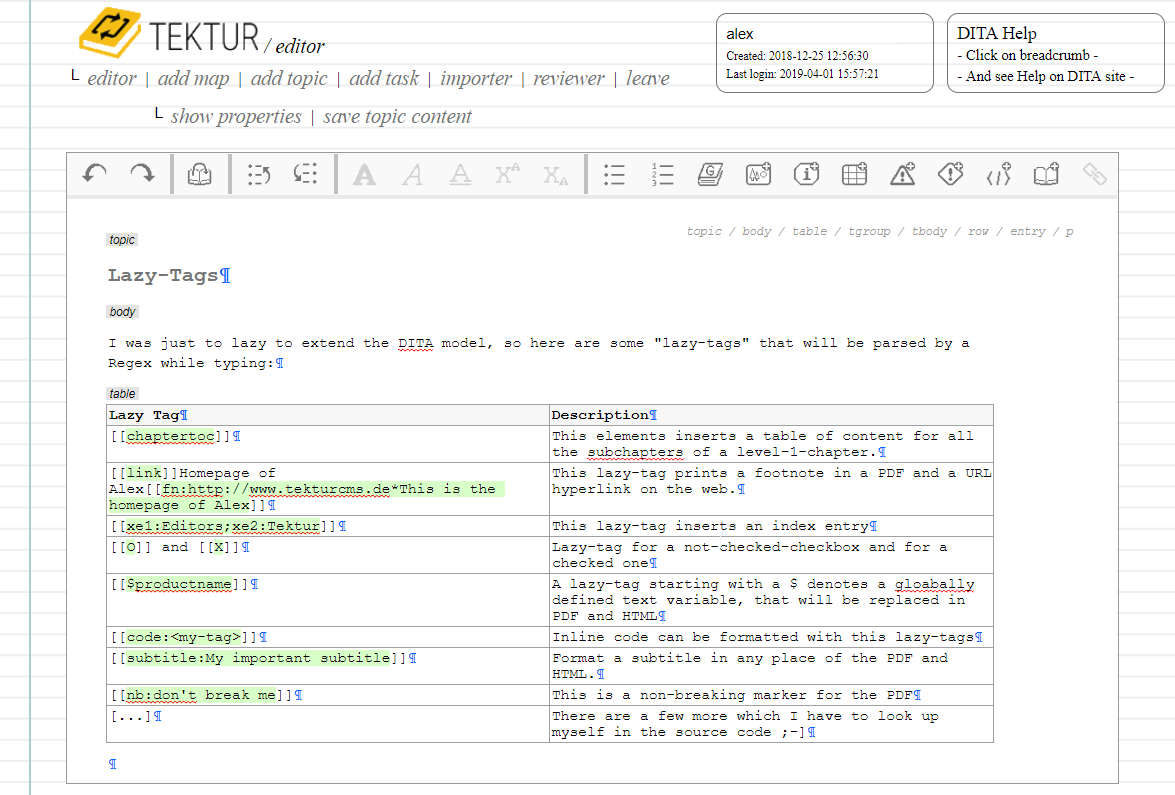
There are also some minor improvements for the HTML format:
-
A button on the header brings up all accepted comments.
-
Commented paragraphs are marked.
-
Chapters that contain comments are marked in the TOC.
-
A panel with comments slides up.
-
Jump to the next and previous pages with the arrow buttons.
-
Download all DITA topics in a ZIP.
March 3rd, 2019
Finalized PDF
I have been working on the PDF layout. Finally I updated to the latest Apache FOP version which makes things a lot easier. This is how a bookmark tree looks in a browser:
This feature is quite hidden in Acrobat DC - for some reason - and the bookmark view doesn't open on initial startup. You have to navigate to a number of dialogs:
The bookmarks act as a TOC:

Hazard statements are now page-wide featuring new icons:
All auto-generated registers come with a description and hyper-link back to the related piece of text:




Note that these registers are not numbered in the TOC in order to distinguish them from other chapters:

Last but not least: Syntax-highlighting of source code - very important to me since I have started writing a book about XSLT and XQuery:

As the book project progresses, I will ask my designer-friend if she is willing to contribute some logos (page header and cover page) and illustrations in order to make the whole thing look more professional :-]
December 27th, 2018
HTML Format & XSLT-Buch
Long time no see! Just added HTML format:
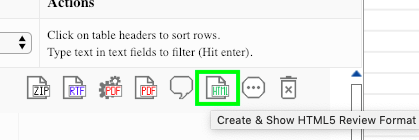
There is still some work to do:
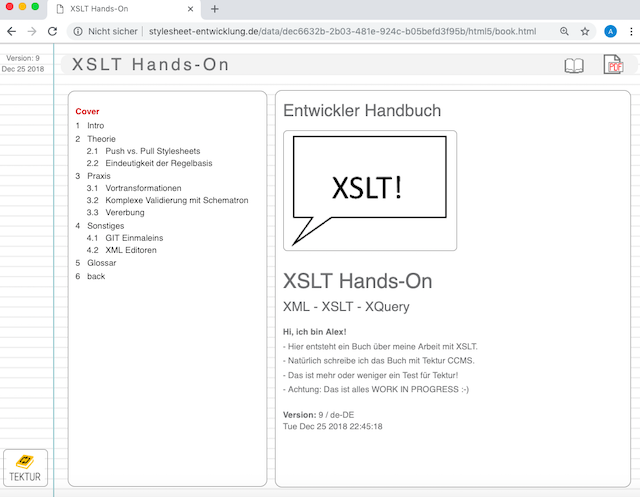
I decided to write a book about XSLT - just for testing purposes:
-
Read XSLT-Buch online (Work in progress)
This will take a while... ;-]
June 26th, 2018
Complete Reviewing Workflow
So here's the complete workflow of the reviewing features. Let's start with a basic scenario:
-
Alice is the editor. She will write a short topic about the installation process of software XYZ. she will put the topic on the review-lists of Bob and Eve.
-
Bob is an engineer. He will review the topic of Alice. While doing that he will find a typo and a content error. He will put a comment next to the affected text paragraphs.
-
Eve is the supervisor. She will check Bob's comments. She will accept the content error but reject the typo.
Let's see this in action:
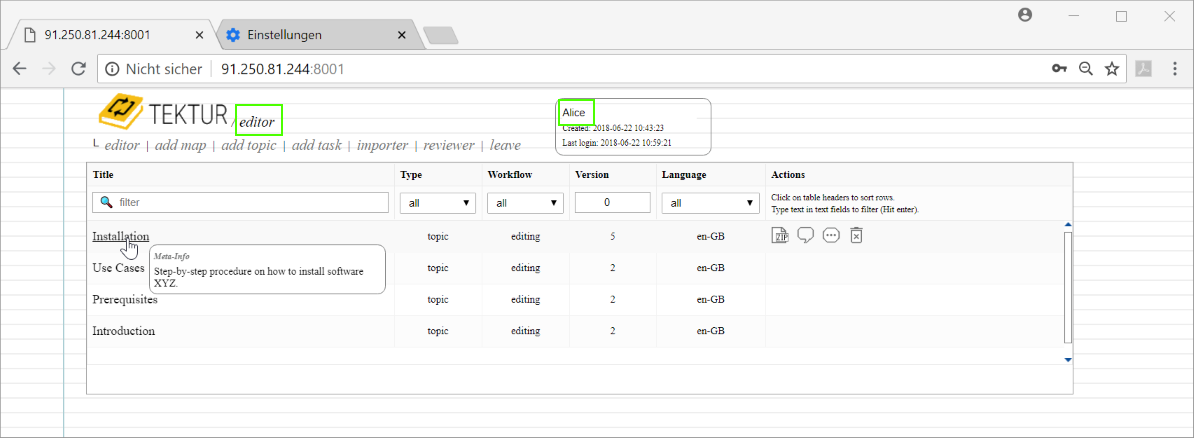
Alice selectes the topic called "Installation" and starts editing...
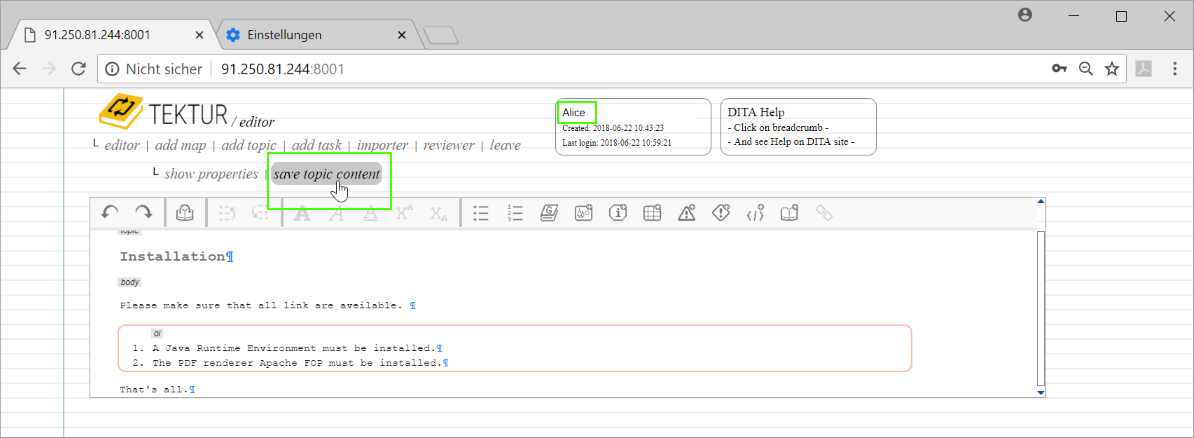
She saves her changes and goes back to her editor-list. She opens the reviewer-dialog...
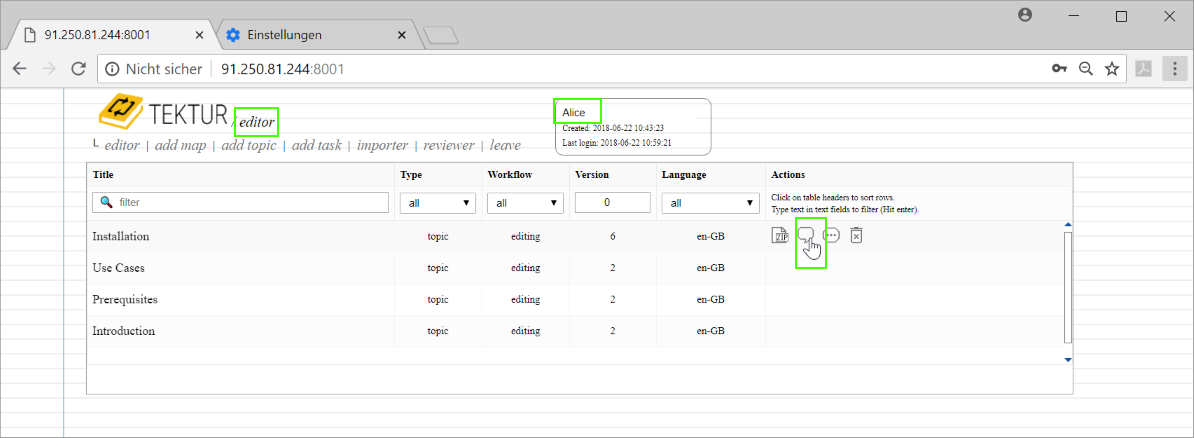
She assigns Bob and Eve a reviewer and approver role...
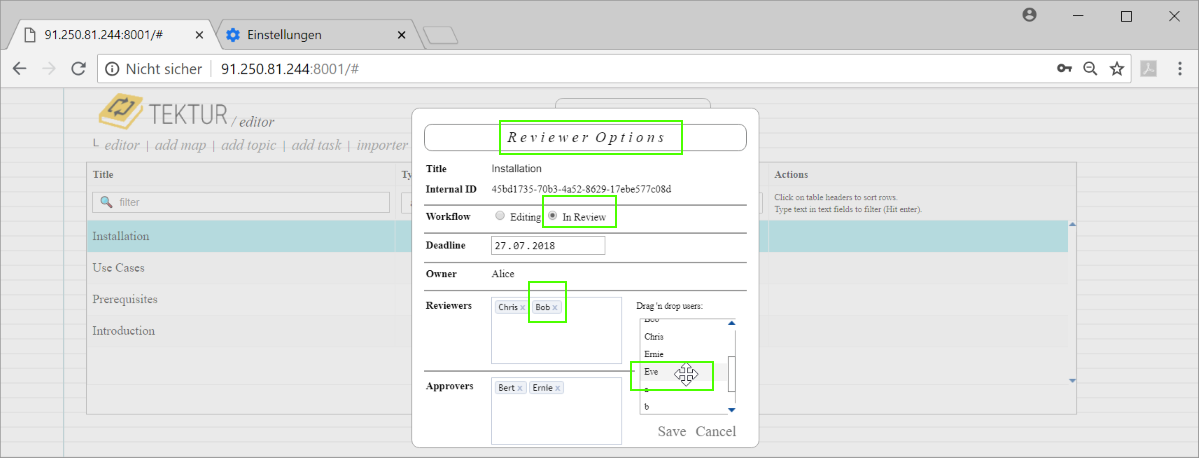
Also, she puts the topic into state "In review". She observes that the workflow of this topic has changed to "review", when looking at the editor-list...
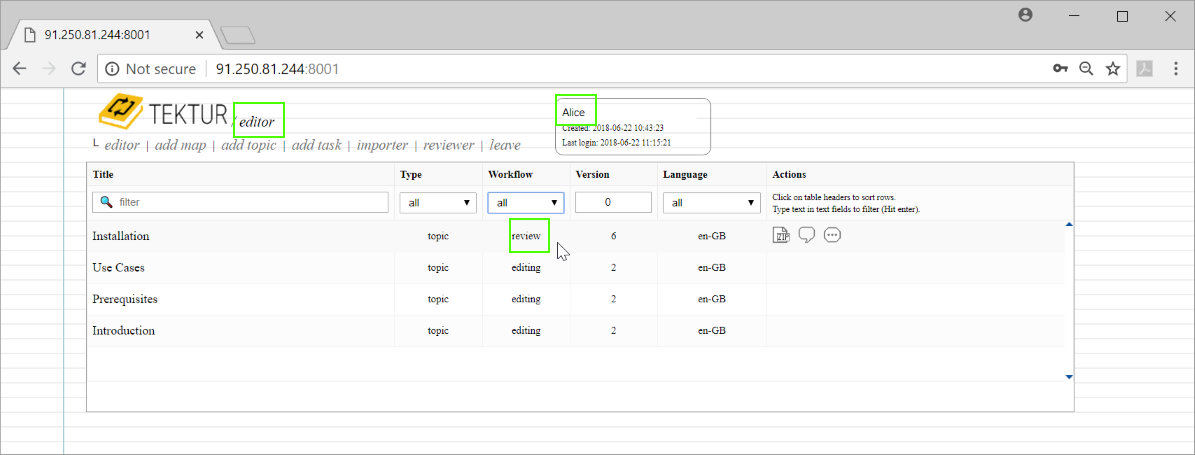
Bob gets notified by email and examines his reviewer-list...
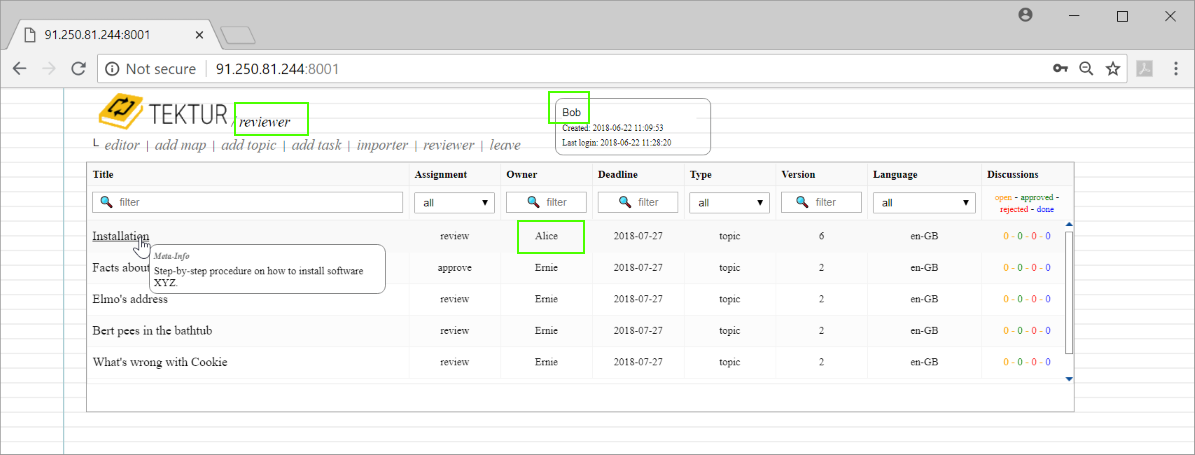
Amongst some topics from Ernie and Bert he also checks out the topic from Alice. He goes straight into that topic and submits some comments...
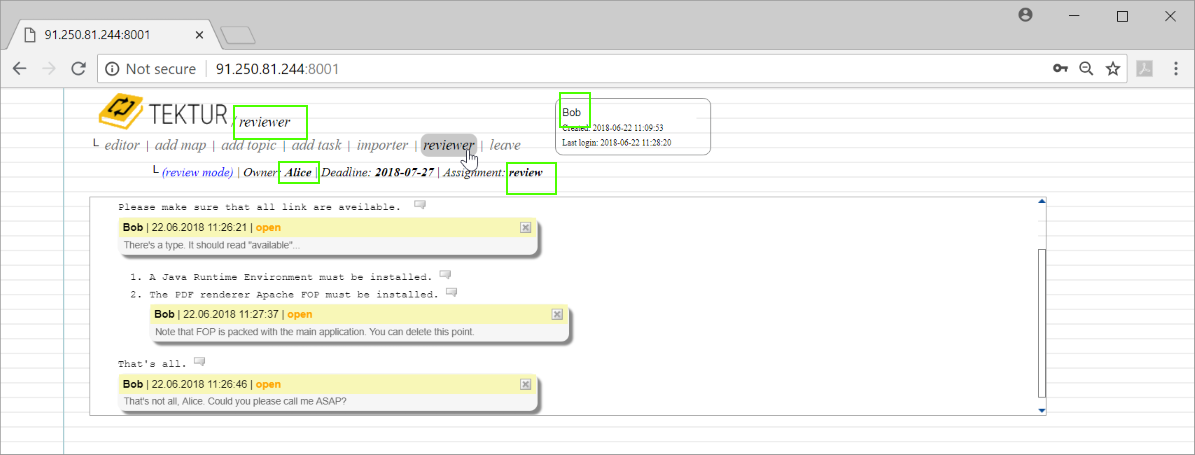
Back in the reviewer-list he notices that there are three open comments...
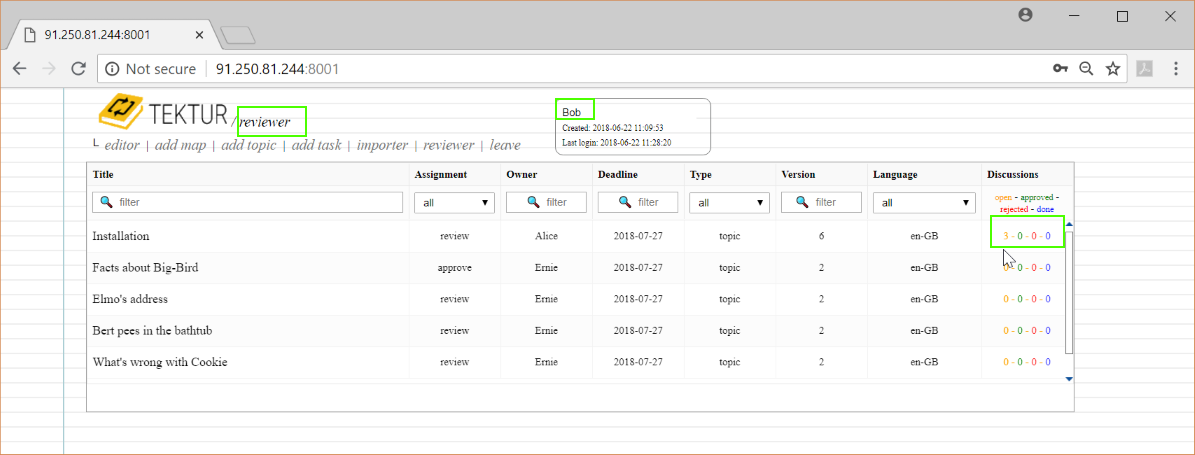
Eve gets notified by email and also checks her review-list. Amongst some topics from Winston and Jules she observes a topic from Alice. She goes right into that topic...
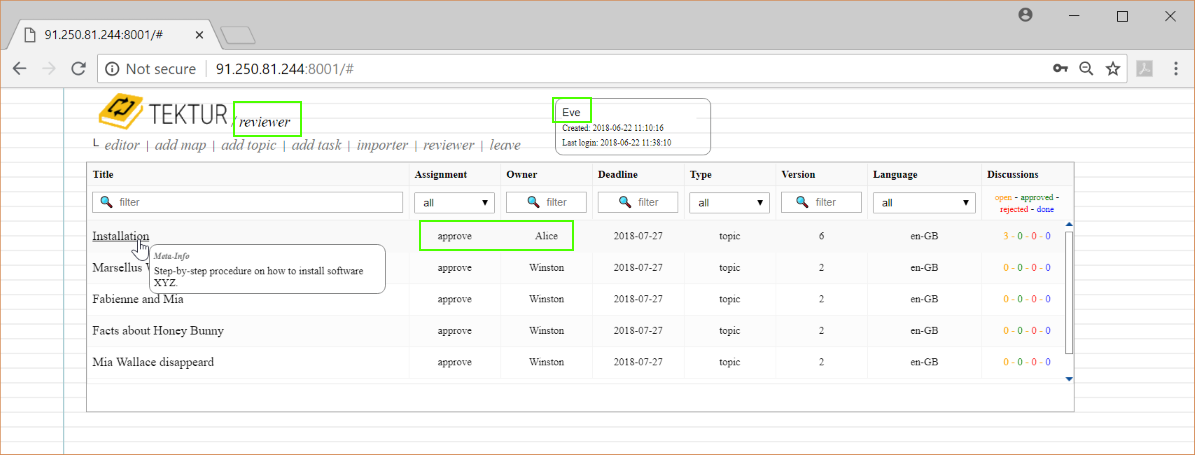
Having the appover role, she may reject or accept the comments. She is okay with most of Bob's comments but does not agree on the typo...
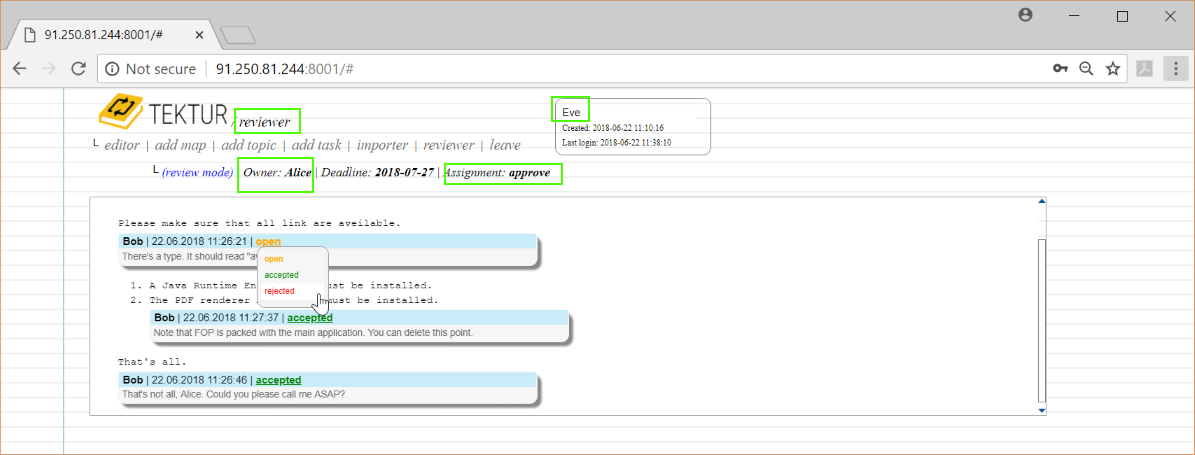
She submits a rejection message...
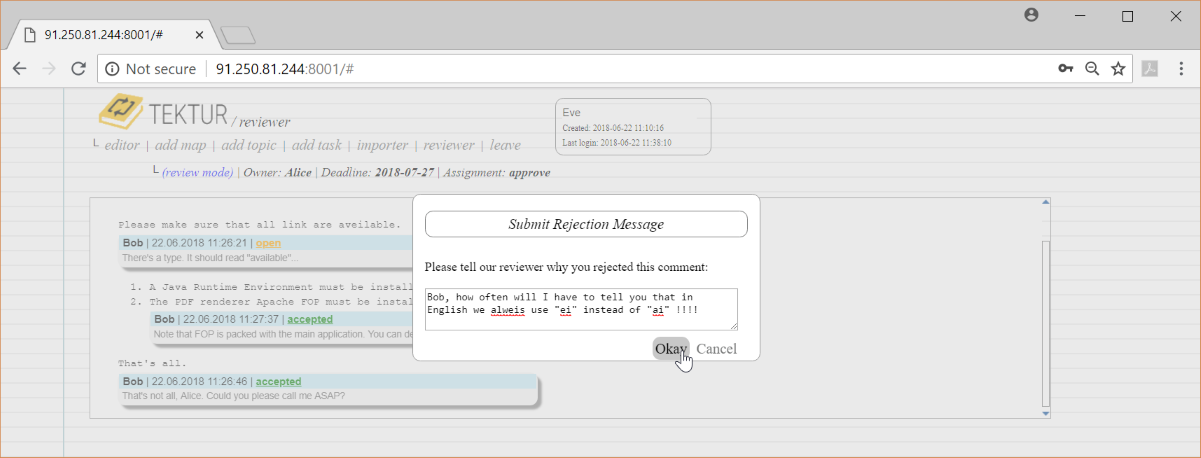
The rejection message is appended to Bob's comment. Bob gets notified by email...
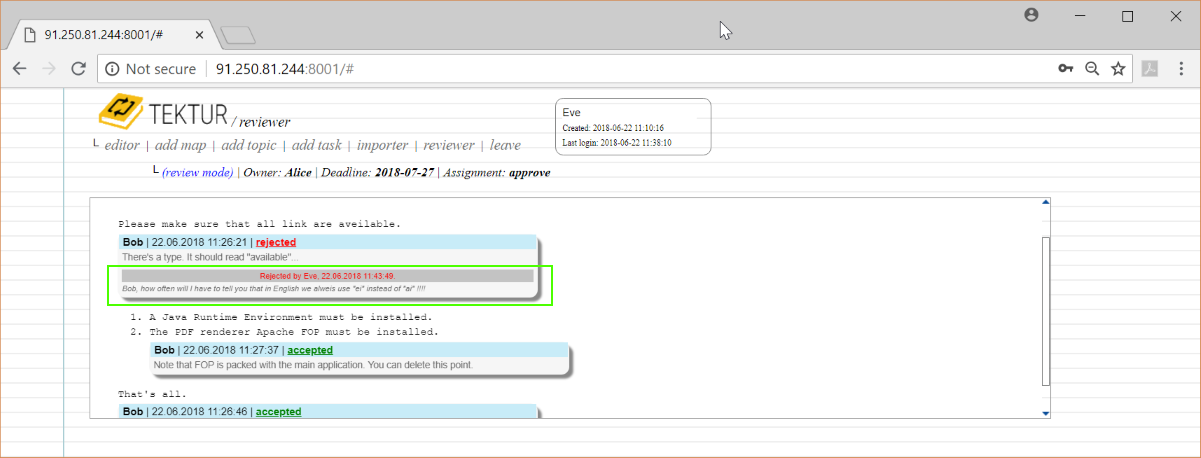
Back in the review-list she checks that the statistic panel is updated...
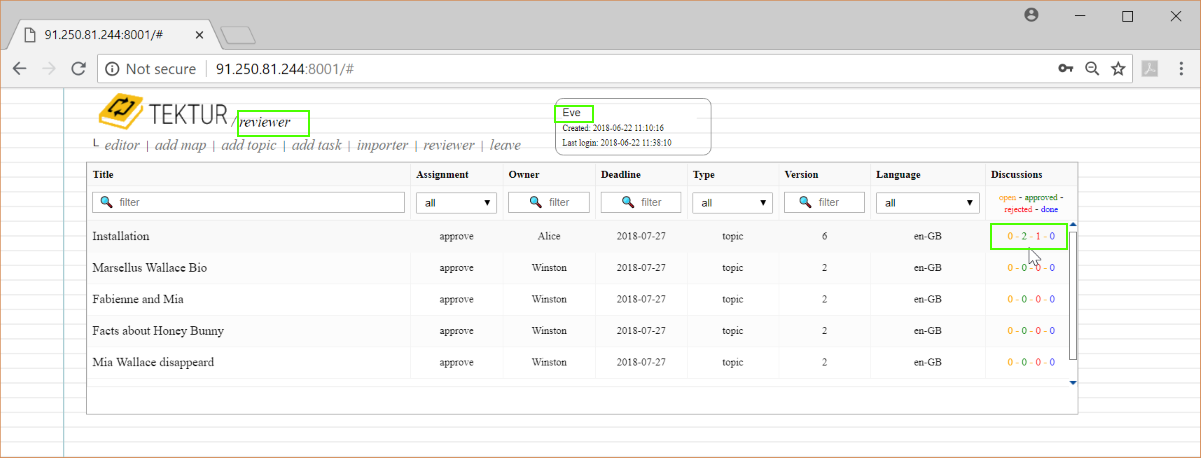
Alice decides to include the feedback from Bob and Alice. She puts the topic back into state "editing". The topic is also removed from the review-list of Bob and Eve...
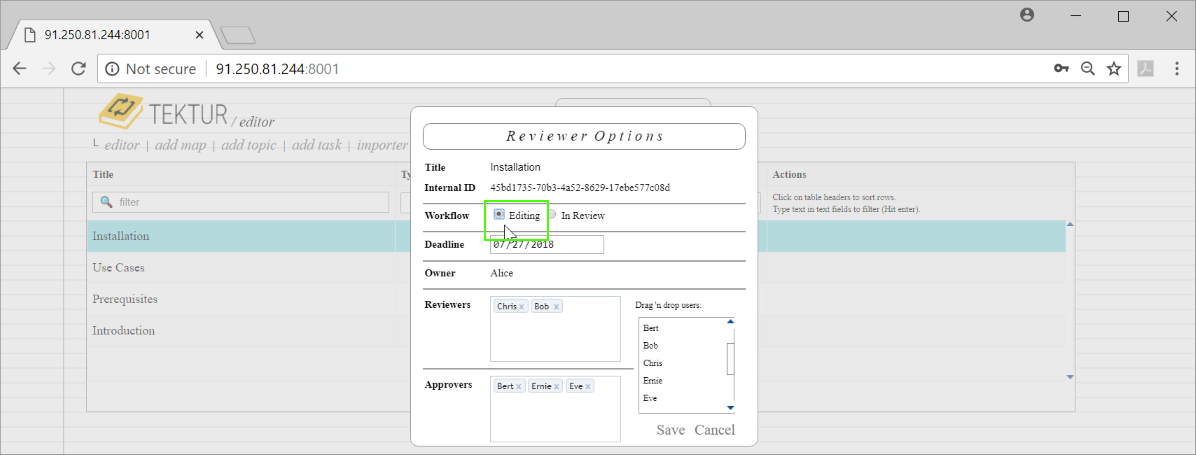
When opening the editor, Alice observes that there is a new button "show comments"...
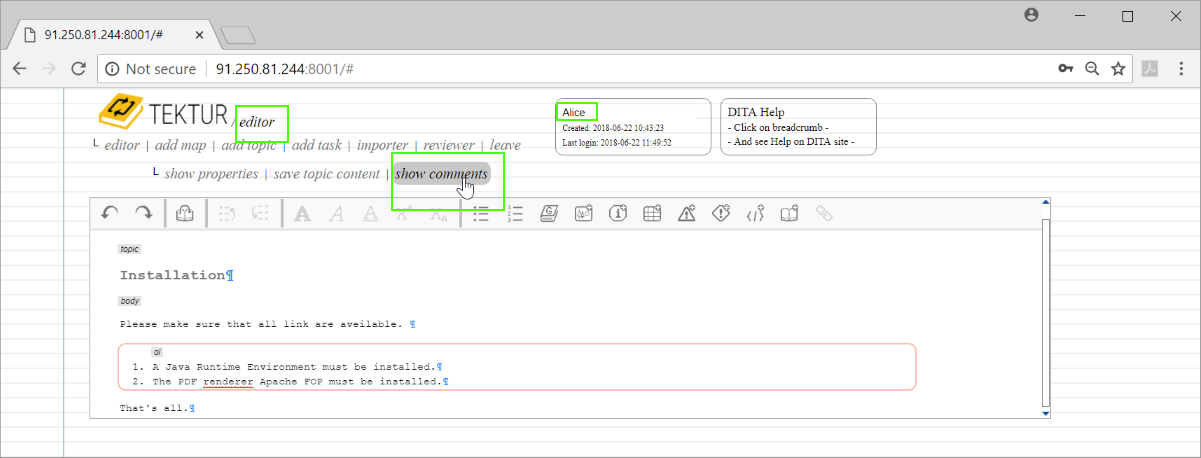
When clicking on that button, she will only see the comments that were accepted by Eve. She will not see the comment that was rejected...
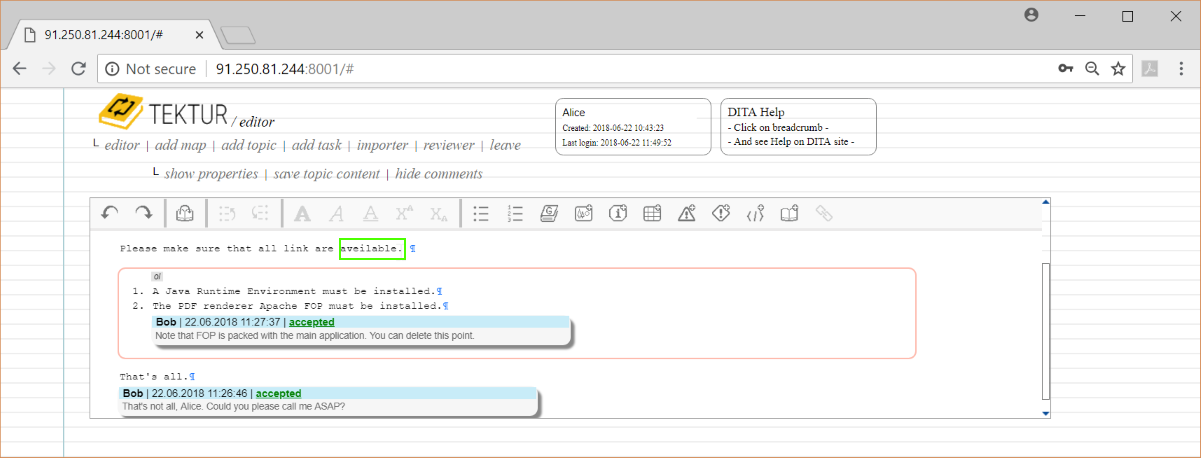
After commiting her changes and corrections, she sets the state of each comment to "done". The comment panel will fade out. Also note that the comments cannot be changed in the editor view...
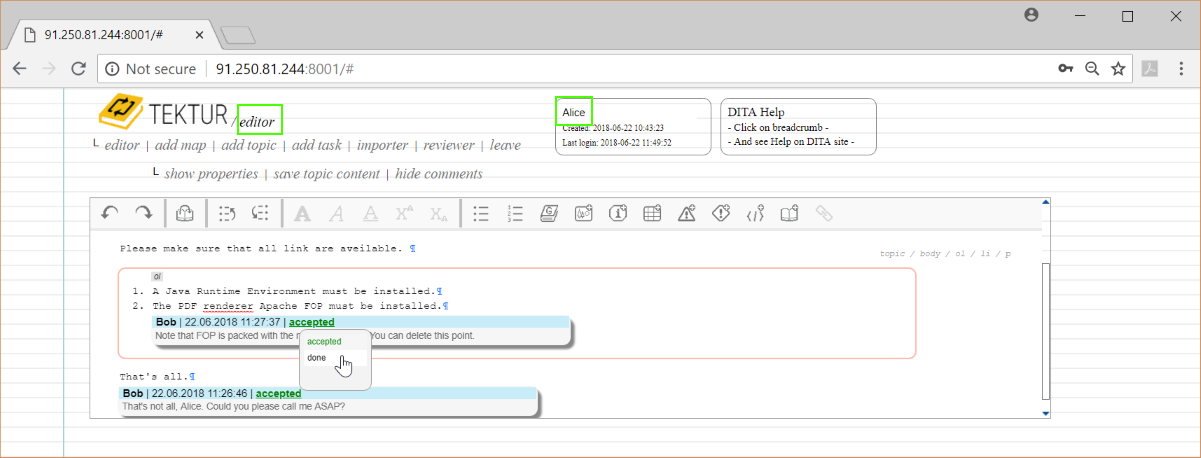
Bob who is the owner of the comments may delete them in the next reviewing step, that will be initiated by Alice, who is the owner of this topic...
May 25th, 2018
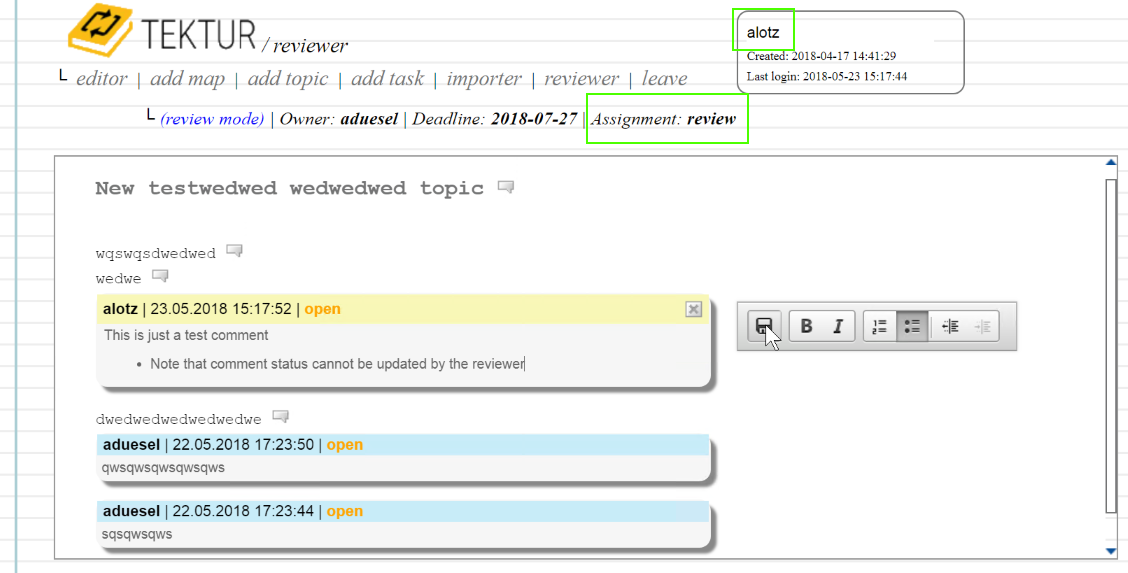
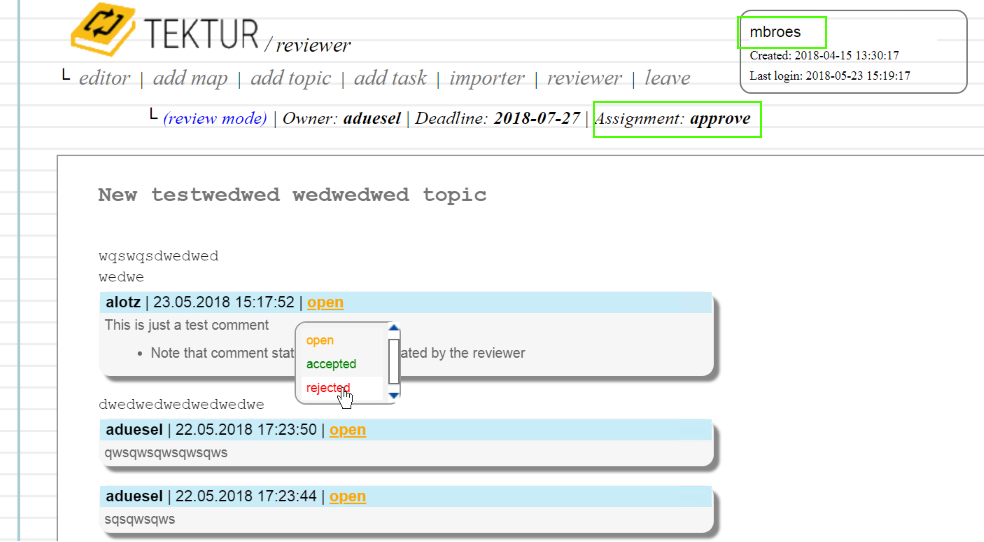
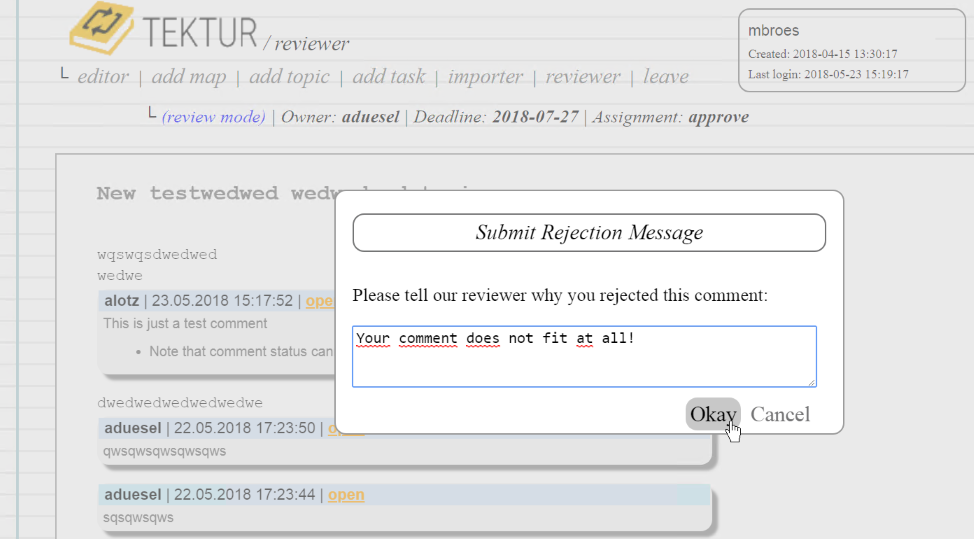
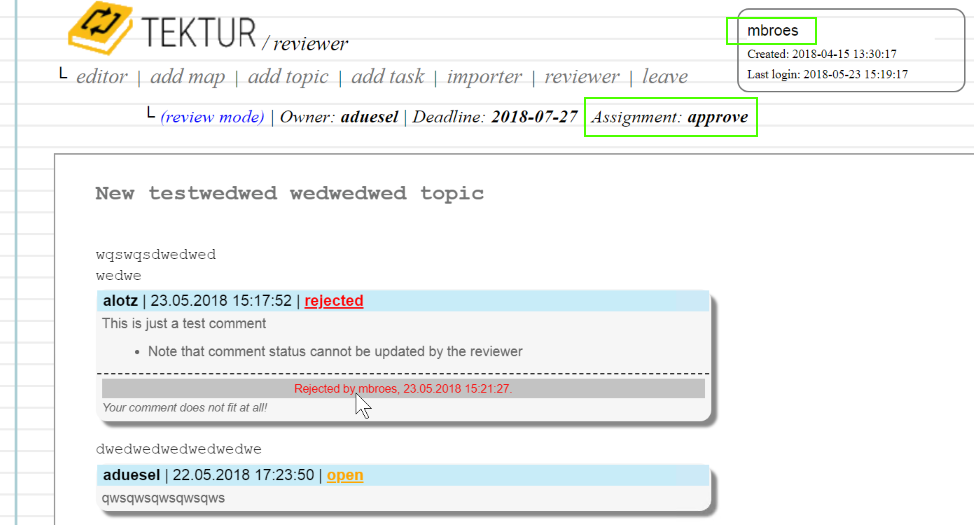
Reject Discussions
Having the Approver role you can reject comments together with a rejection message. The Reviewer will be notified by eMail about the changes.
April 19th, 2018
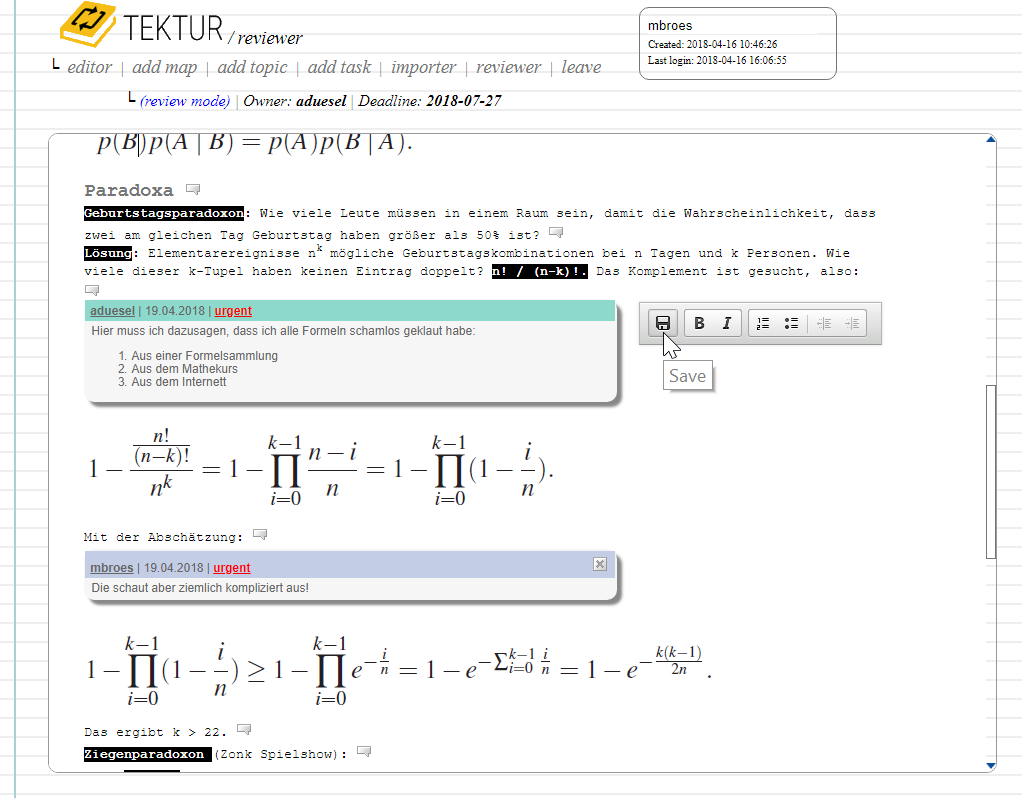
Manage Discussions
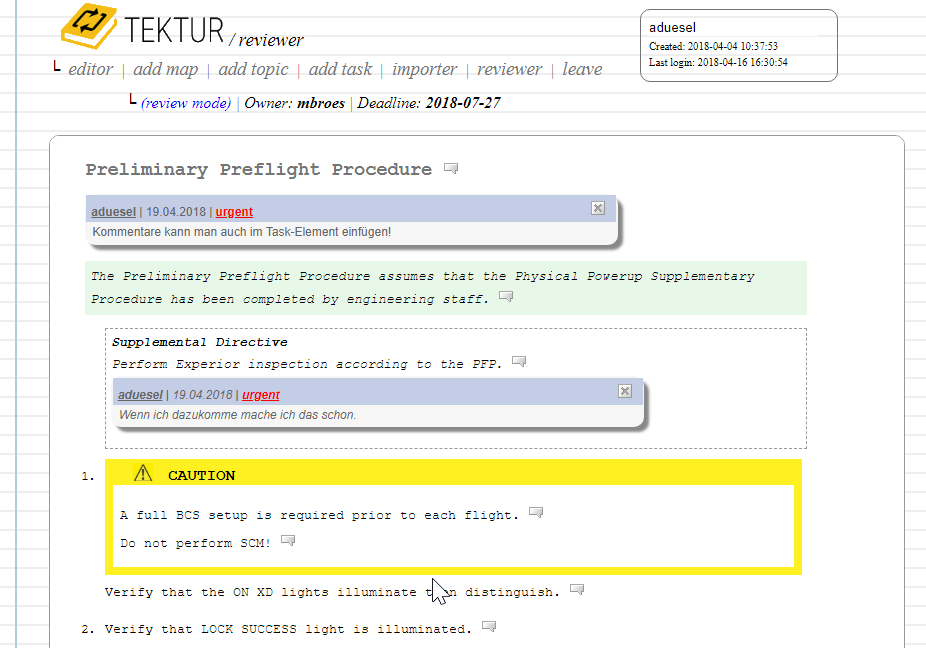
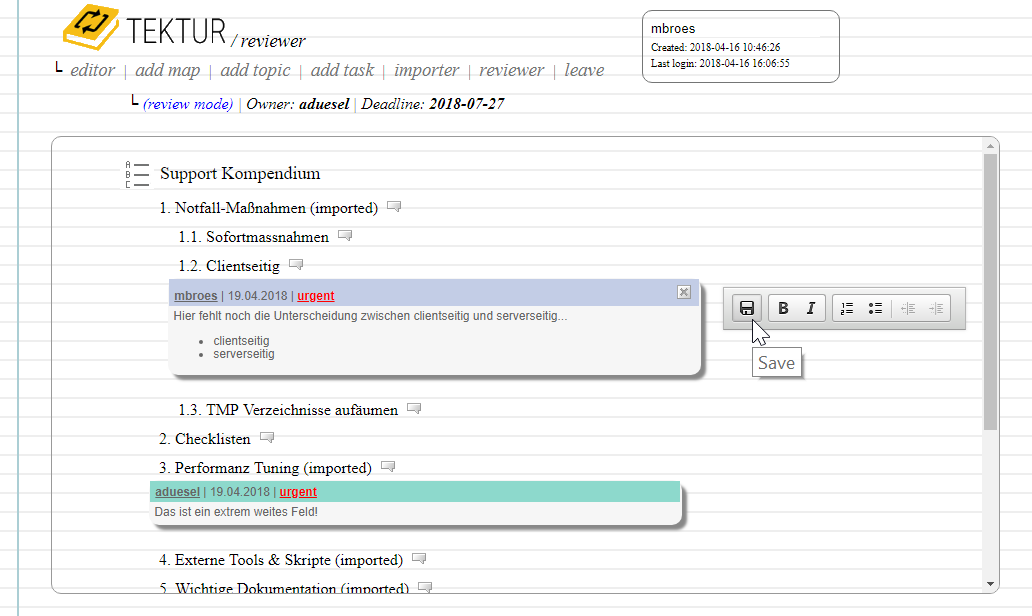
You can add and remove comments to/from any piece of text using an inline editor widget. This is how it looks like:
March 10th, 2018
Reviewer-Listing & Review-Editor
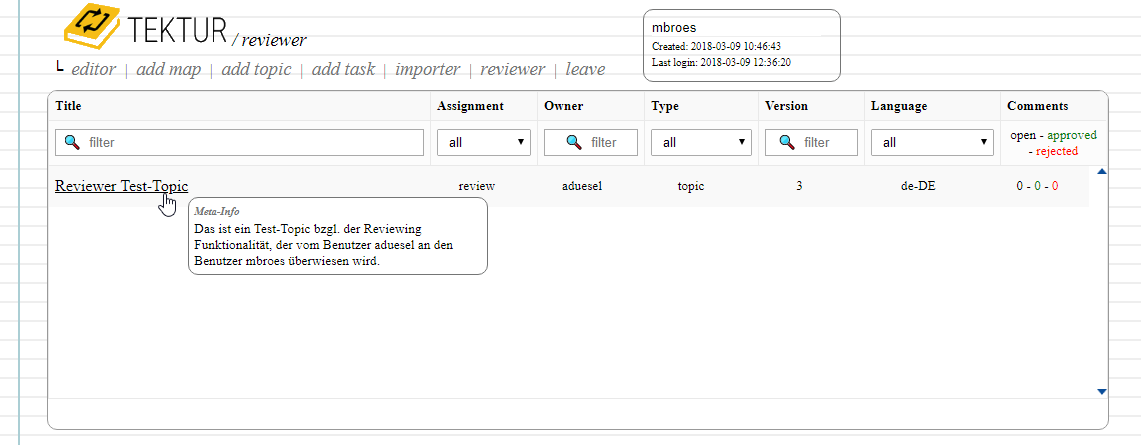
Finished with the reviewer listing. There are columns for the assignment type { approve | review } and for the number of comments. All columns are filterable and sortable:
When you click on the topic title you will get to the reviewer screen:
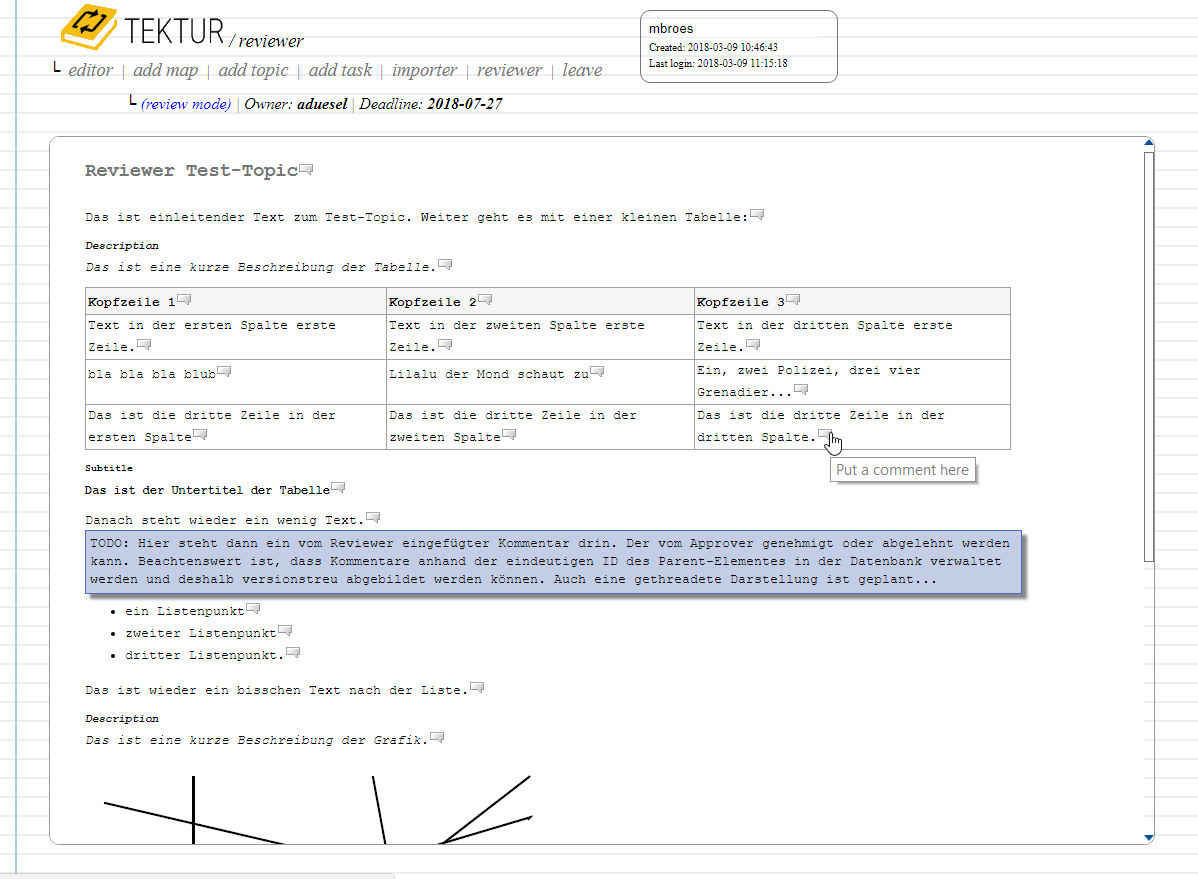
Every piece of text is decorated with a little speech bubble icon. You can put comments by clicking on such a bubble. This is where the story ends for now. To be continued in April :-]
February 25th, 2018
Review & Approval
Started working on the workflow features. The first version will be quite simple. For now, there is a speech bubble button that lets you configure approval and review roles for each topic, task and map:
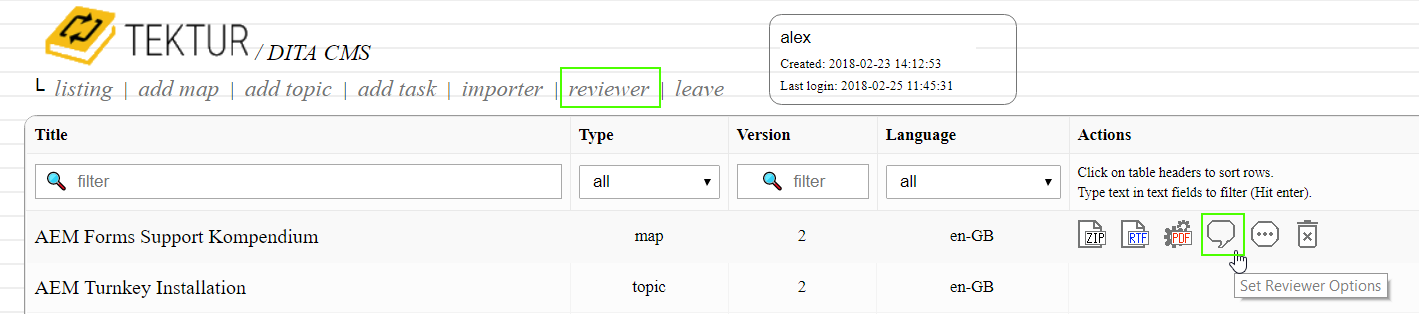
There is also a new entry in the top menu called "reviewer". If you click it, then you will get to your list of items that you were assigned to by your peer editors. The configuration is located in a popup dialog:
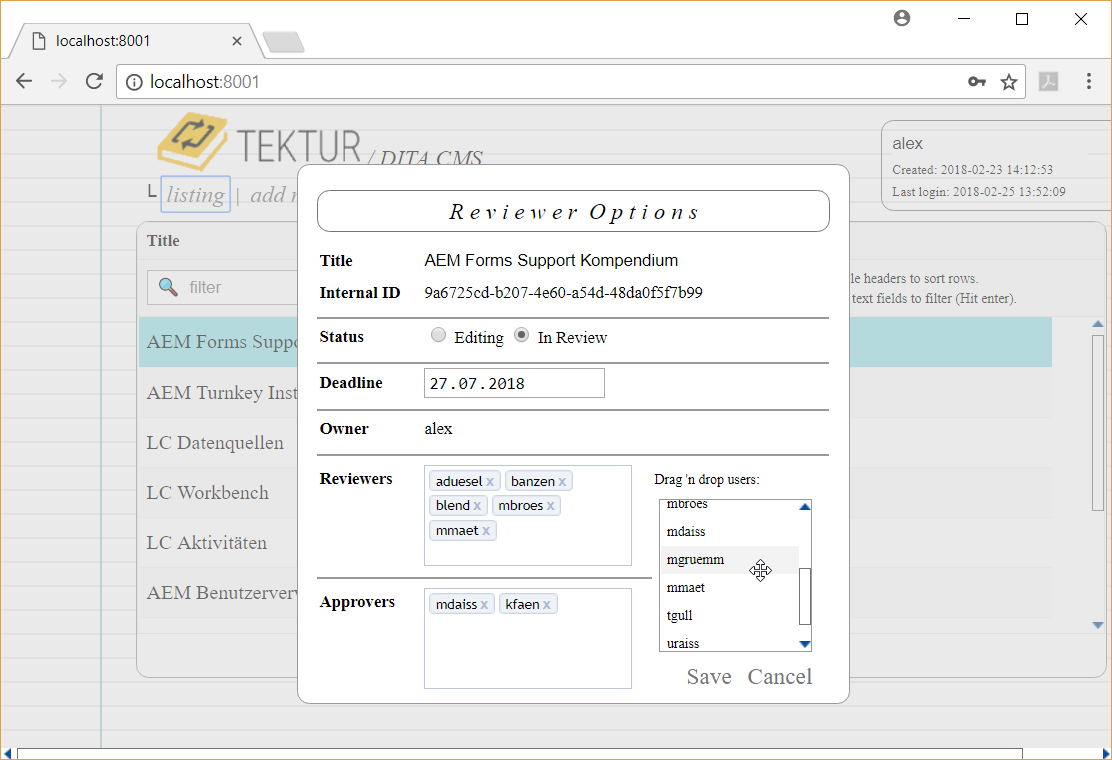
A Tektur document can reside in two different states:
-
Editing: Approval and review is blocked for all users.
-
In Review: The document is in read-only mode, but:
Reviewers can put change requests on text paragraphs. Approvers may accept or reject these change requests together with an explanatory statement. If a change request has been rejected then a notification will be sent to the reviewer. Also, deadline reminder mails will be sent.
February 24th, 2018
RTF (Word) Import / Export
Added a new output format. It's RTF that you can open and edit with your Micro$oft Word Processor.
RTF will not be cached and created every time you click the button.
I put another tab on the plain-text importer dialog (also note the fullscreen button) in order to import RTF content from Word or from a website:
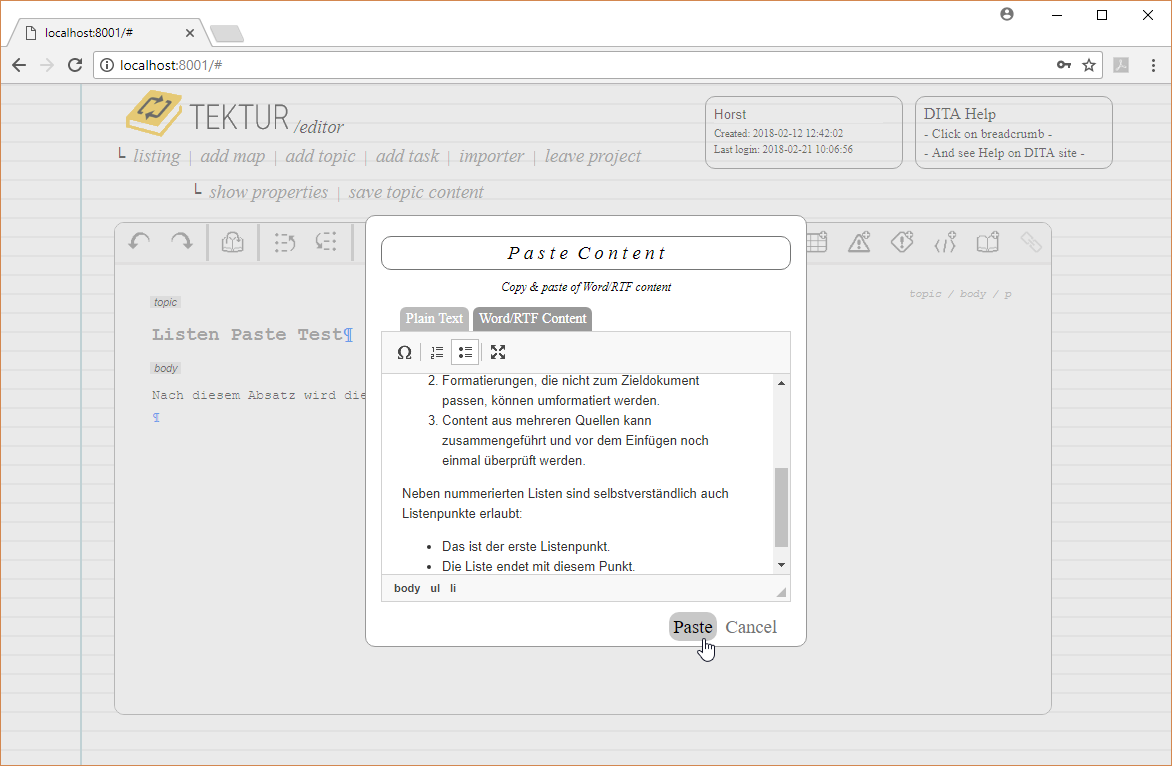
Paragraphs and simple list structures are currently supported. All other content will be merged into a plain-text block. This is how the input of my test case looks like (I copied this piece of text into the popup dialog):
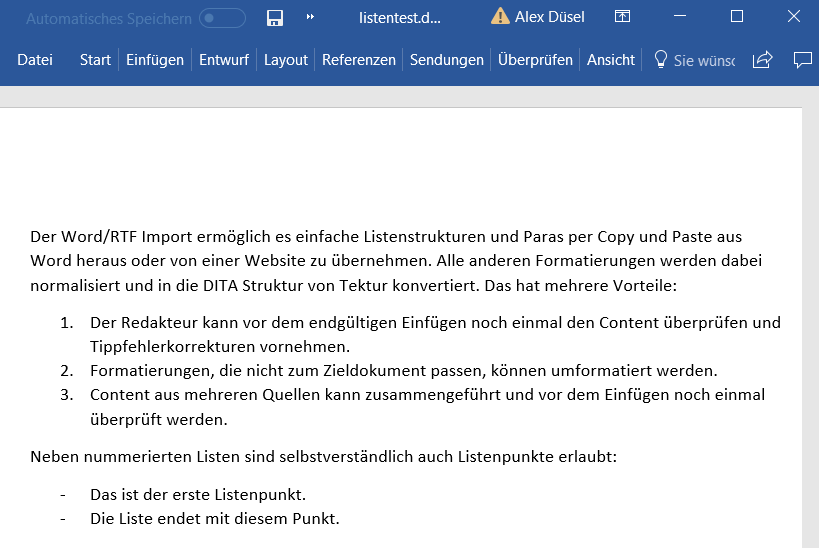
Conversion to DITA is done on-the-fly with the following result:

There is also a configurable widget for inserting special characters:

BTW: I was not able to put a decent filter icon into the input boxes of the lists because JSGrid does not provide this functionality.
Thus, I was searching in the UTF-8 character set and found a magnifying lense! This is how it looks in my source code editor:

The result looks like this:
Does not perfectly fit together with the other icons but at least there is an icon :-]
February 8th, 2018
Versioning
View a previous version of a topic, task or map. Just click the "More" button located on the action bar:
The popup dialog lists all previous versions together with a timestamp:
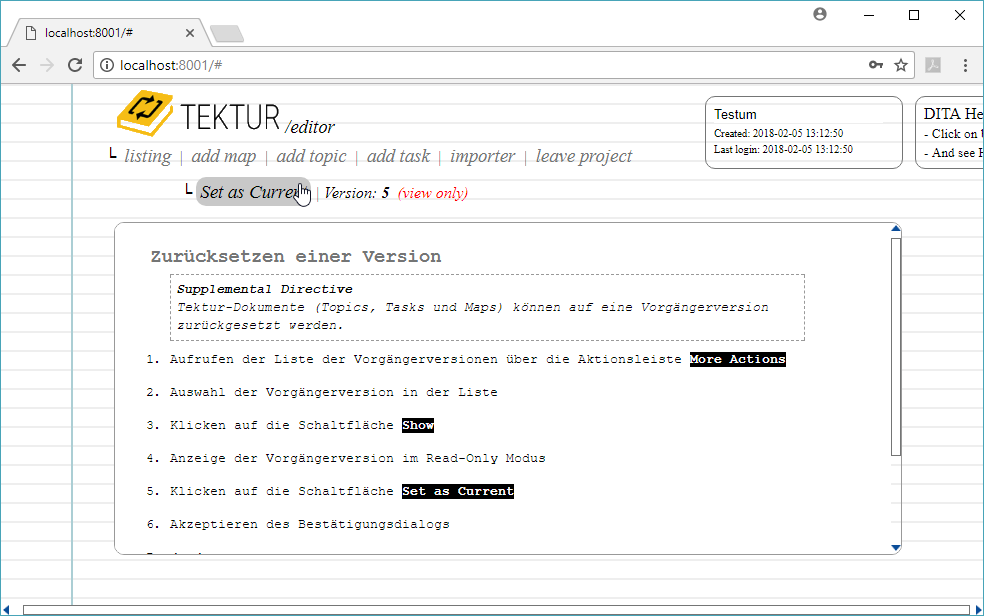
Show a previous version in read-only mode:
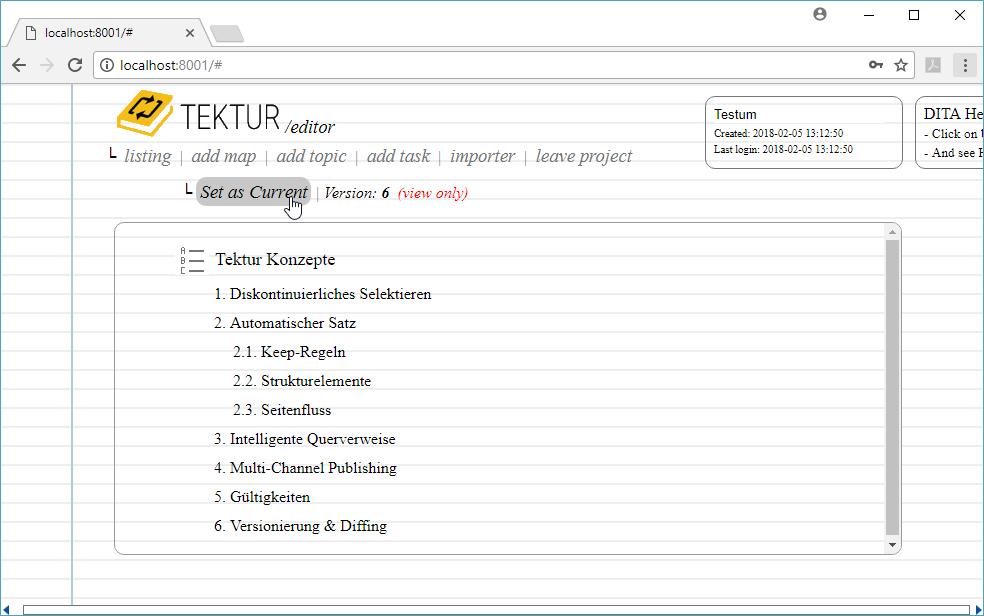
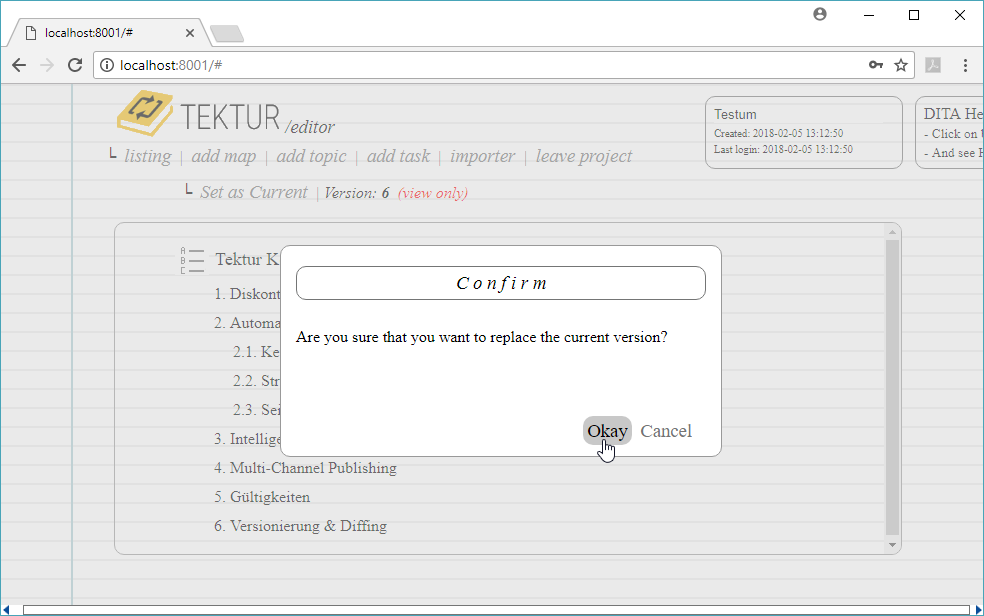
When you click on the button Set as Current then the current version of the document will be replaced. You will be prompted for confirmation:
This is how read-only mode of a topic/task looks like:
January 13th, 2018
Function Follows Form
Yes, I know! It should be exactly the other way round... But I was just too lazy to think about the GUI concept again.
Currently there is a main panel with a listing or an editor on it. It depends on the state of the application. There is also a popup dialog which shows up in the middle of the screen.
Reworked this dialog in order to improve the UX. See how it looked before:
That is okay for testing... But in production, the user input must be validated - even better: The user should only be able to select reasonable values.
This dialog is definitely to small. I worked around this by attaching a tooltip on the right side. This is how it looks now:
Also, stumbled across some cool new HTML5 features:
There is an <input type="range"> now. No need for implementing your own Javascript slider anymore. Not to forget the new <input type="color">...
December 27th, 2017
Some more random usability features
1.) You can add a description to each topic, task or map in the properties section.
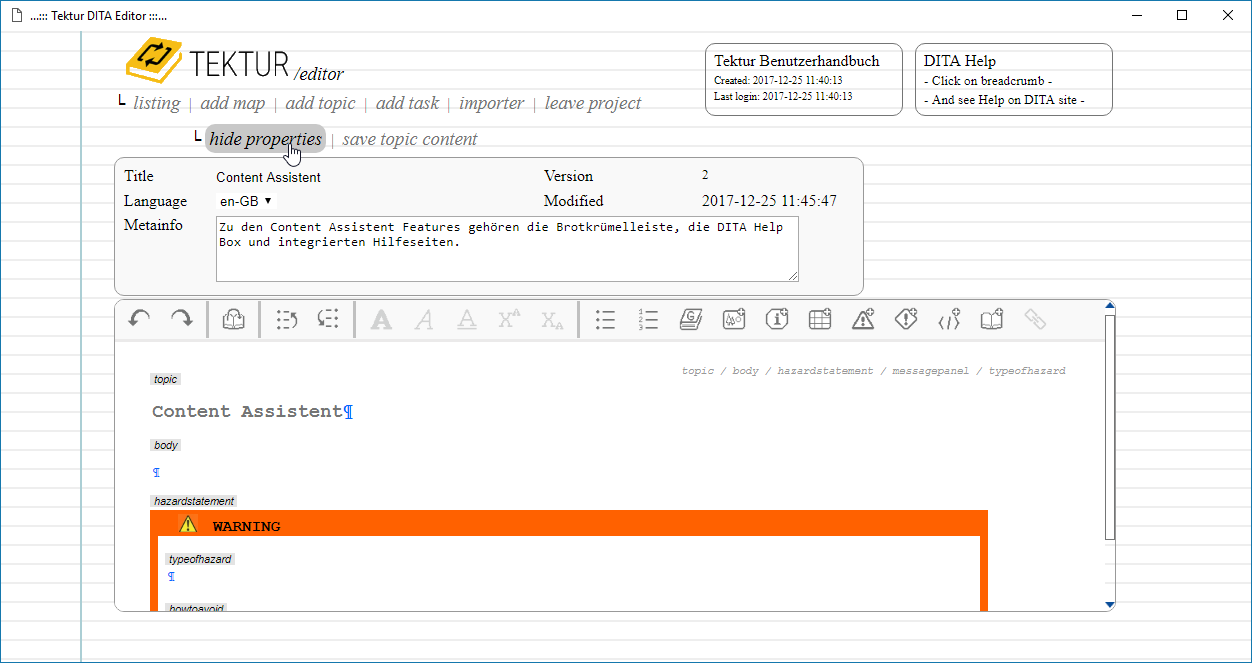
It will be displayed as a tooltip when hovering over the topics listing
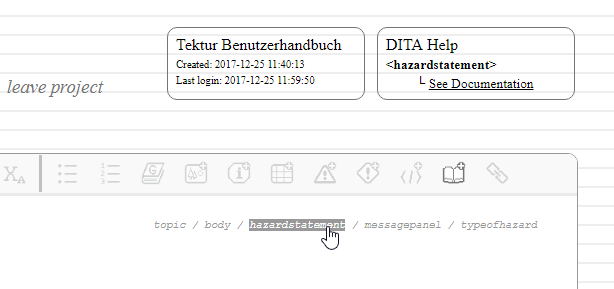
2.) When clicking on a breadcrumb the DITA Help box is updated with a link to the corressponding documentation on the DITA homepage.
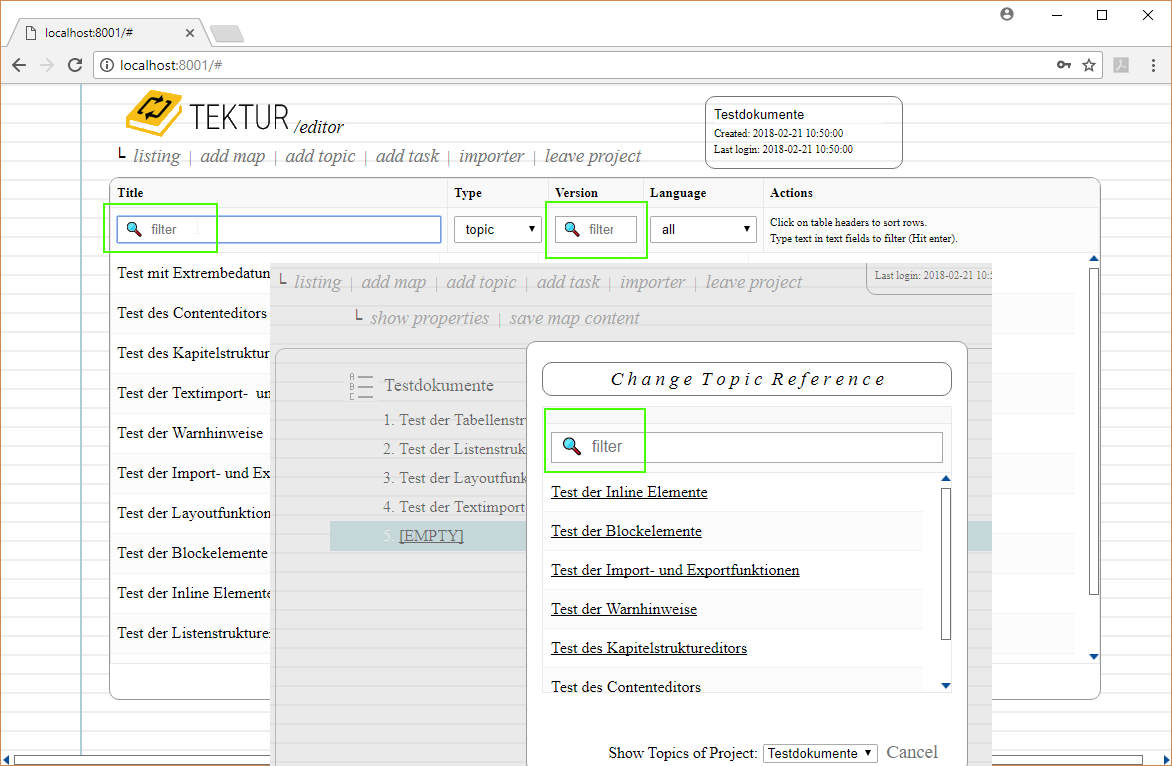
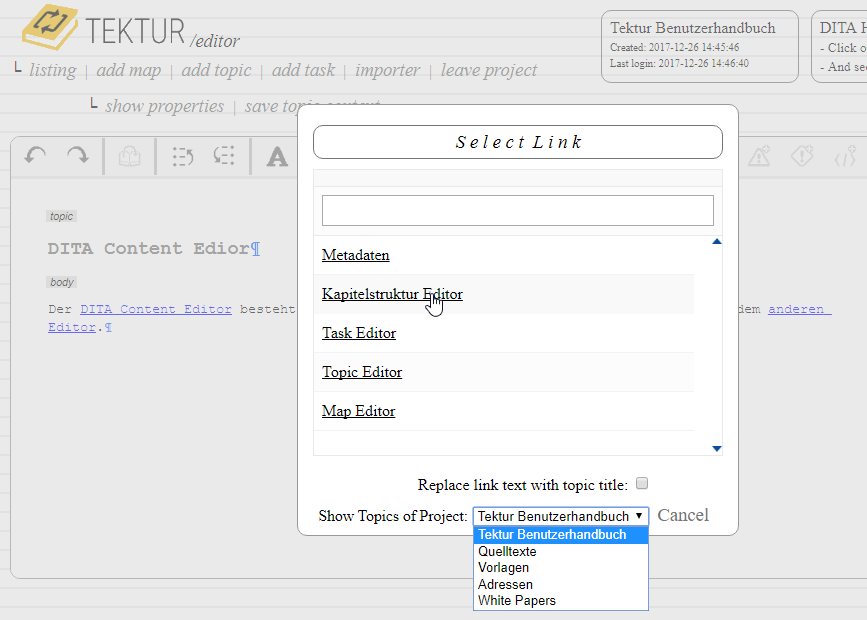
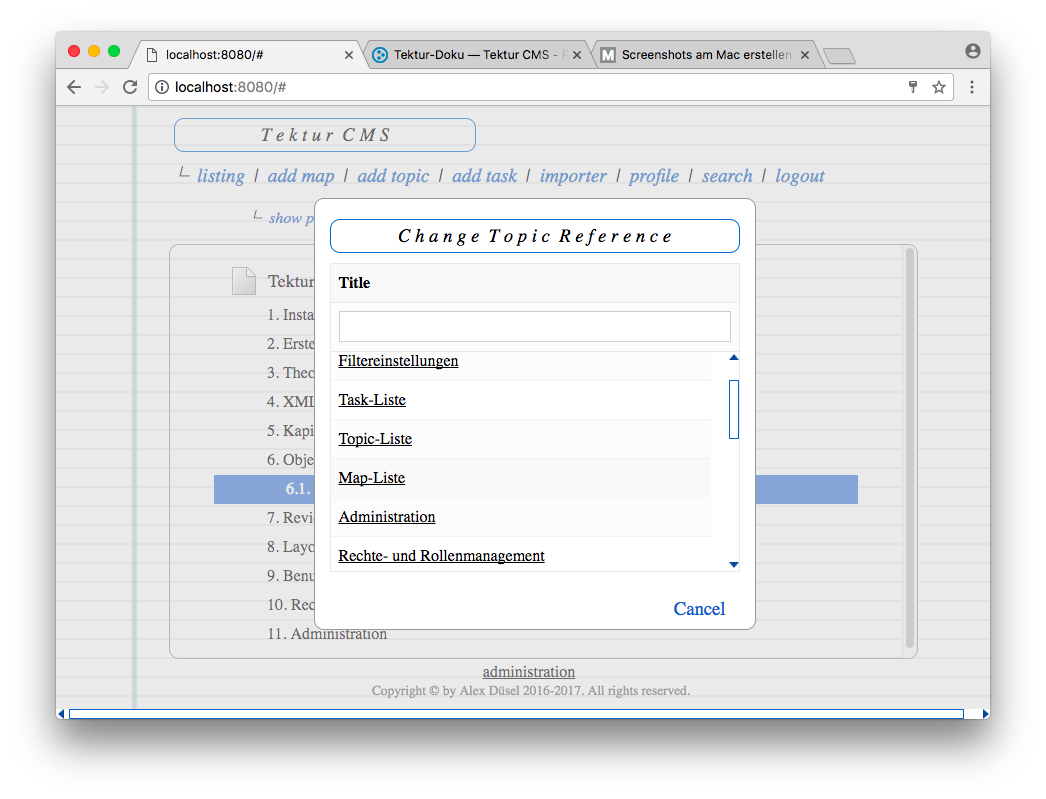
3.) Changing a topic reference in the map view lets you also select topics from a different project. Note that the text input field at the top of the dialog box can be used to filter the result list.
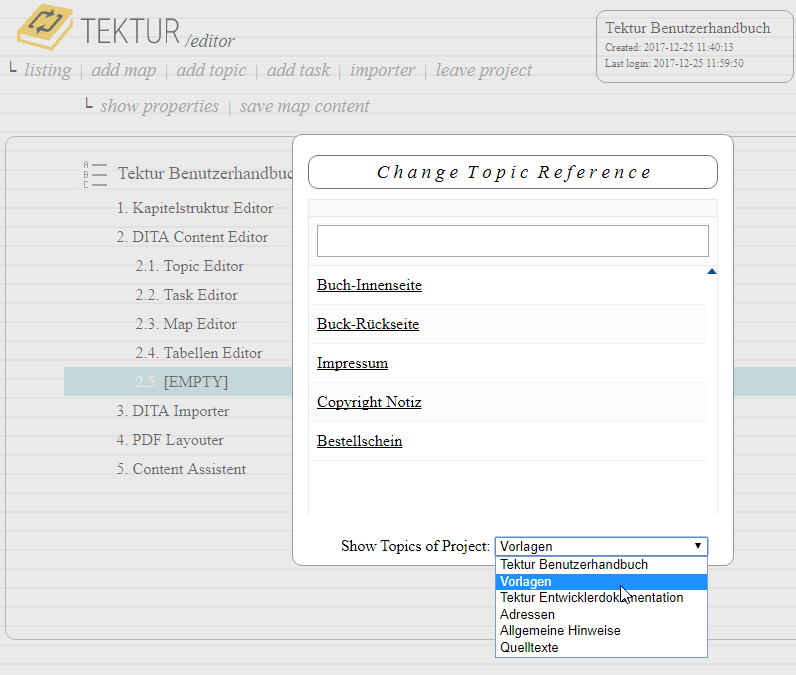
A topic that is linked from another project will be marked as "external".
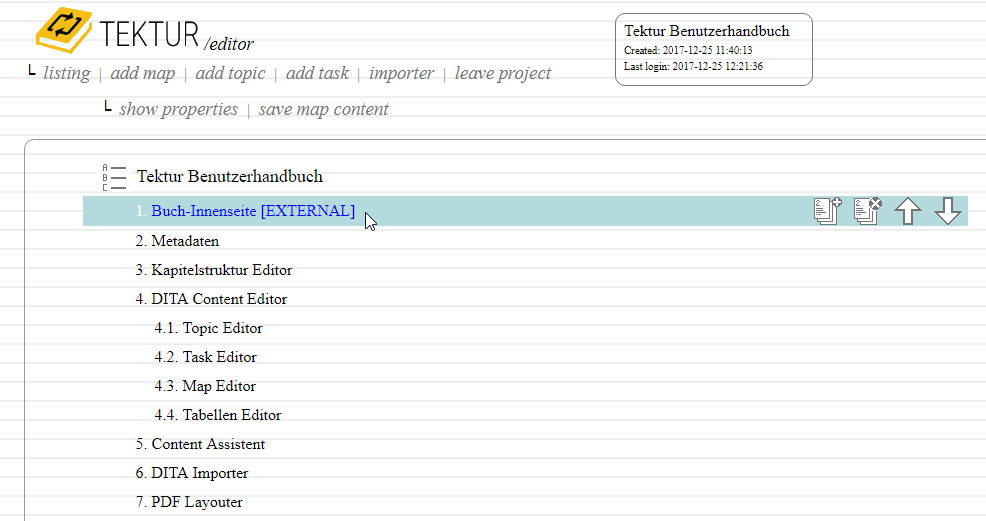
4.) Links may reference topics from another project. Note that the link text will be updated with title changes without a refresh.
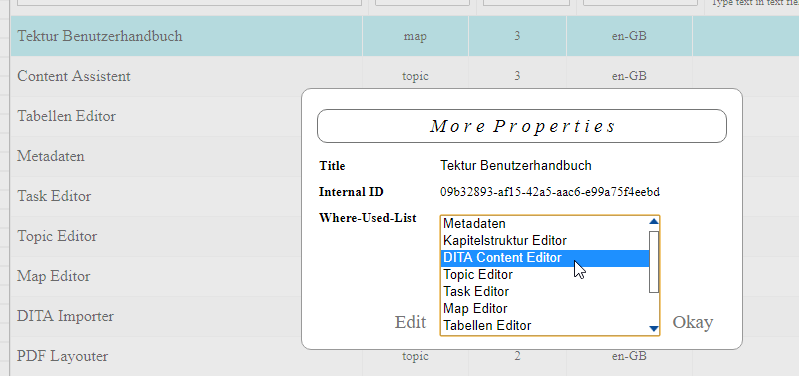
5.) There is a "more info" button next to each list entry.
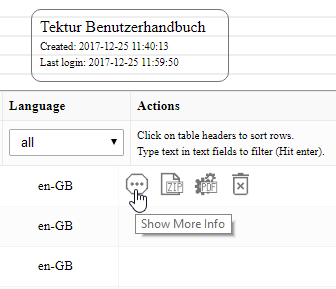
When you click on this button you will see a little dialog, that displays two fields:
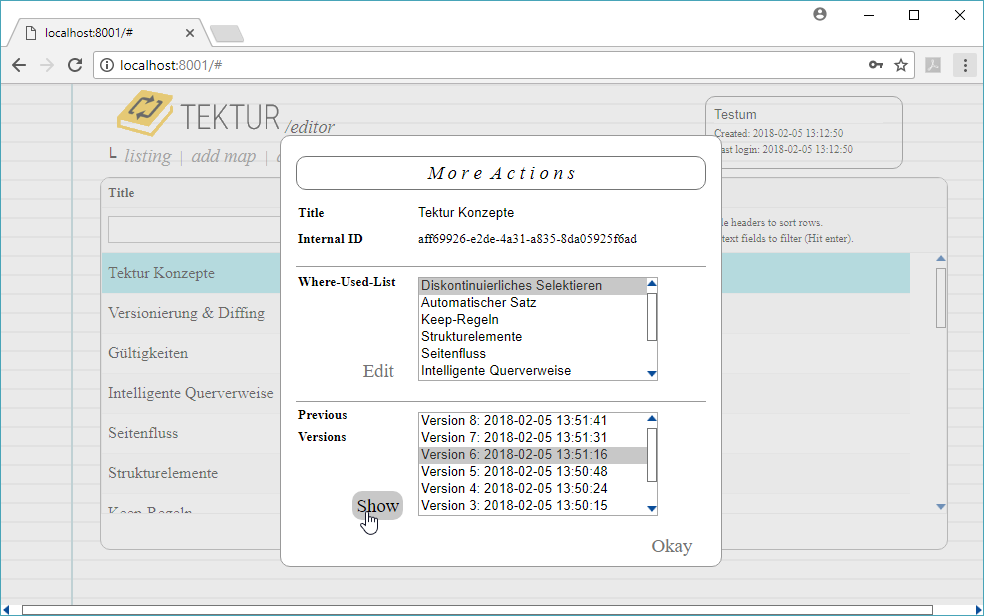
- The internal ID of this topic, task or map (important when debugging).
- The "Where-used-list" with all cross-references to this topic.
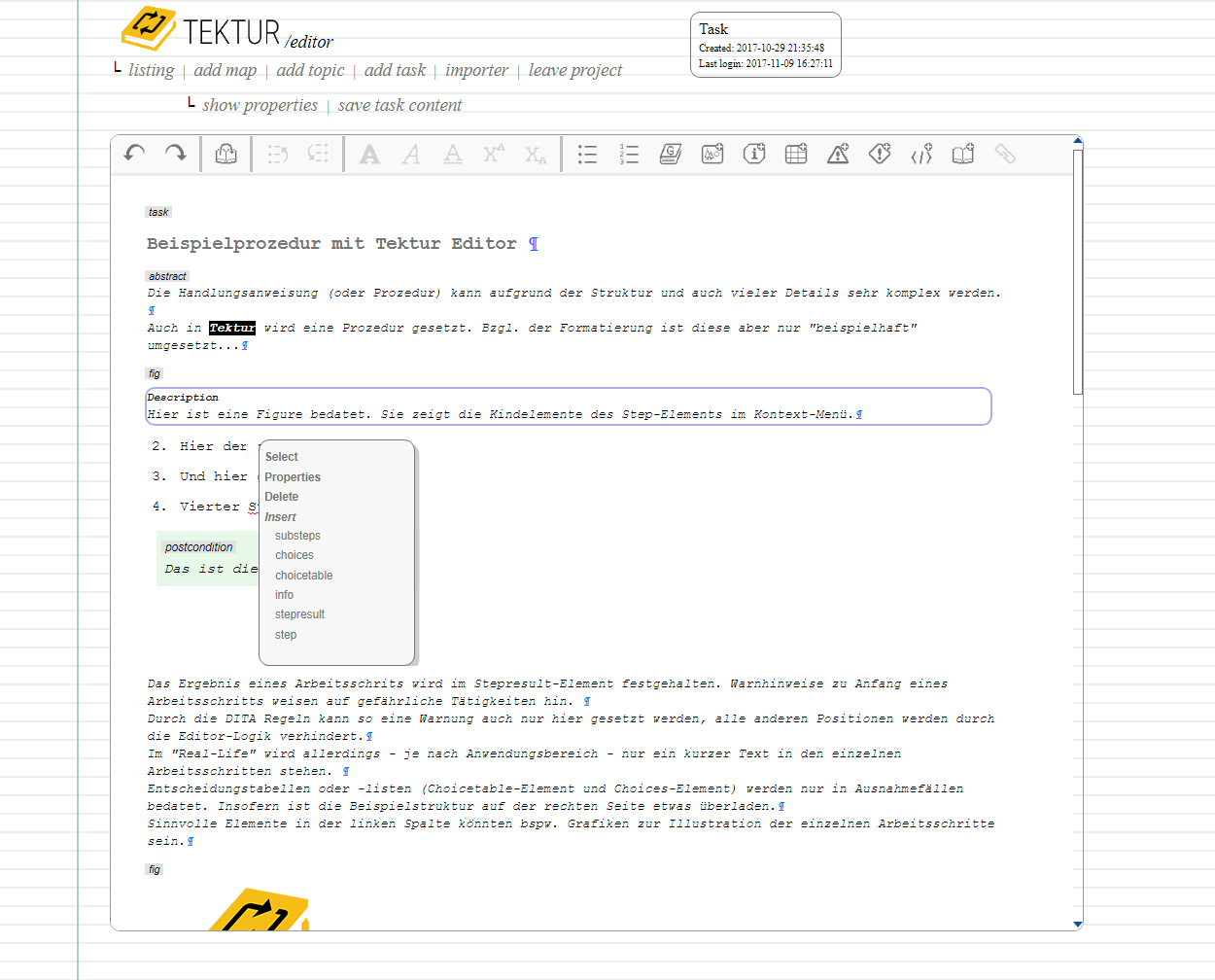
November 9th, 2017
Same procedure as every year
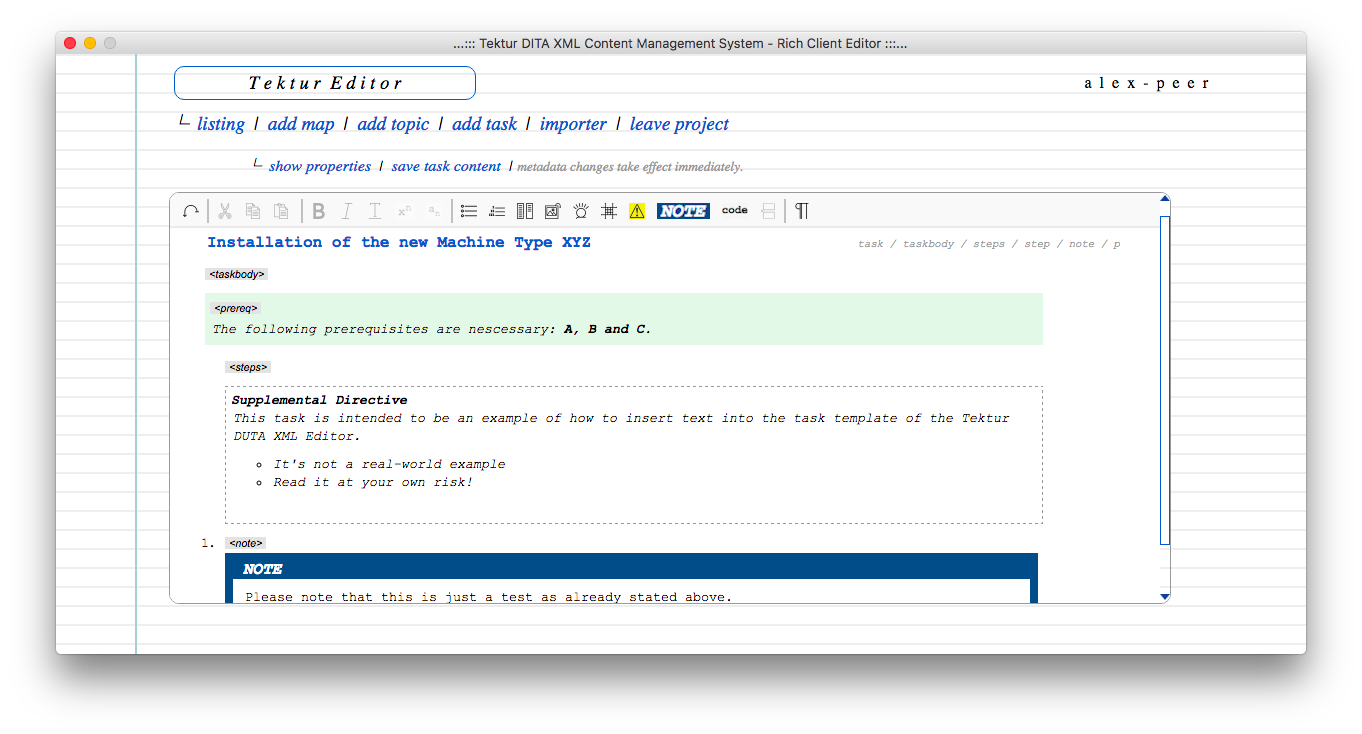
The task is probably the technical editor's most beloved element. Check out the specification on the DITA homepage. Also note that the PDF layout is work-in-progress (rendered by an "old" version of Apache FOP, v1.0)

Looks also good in the editing view:
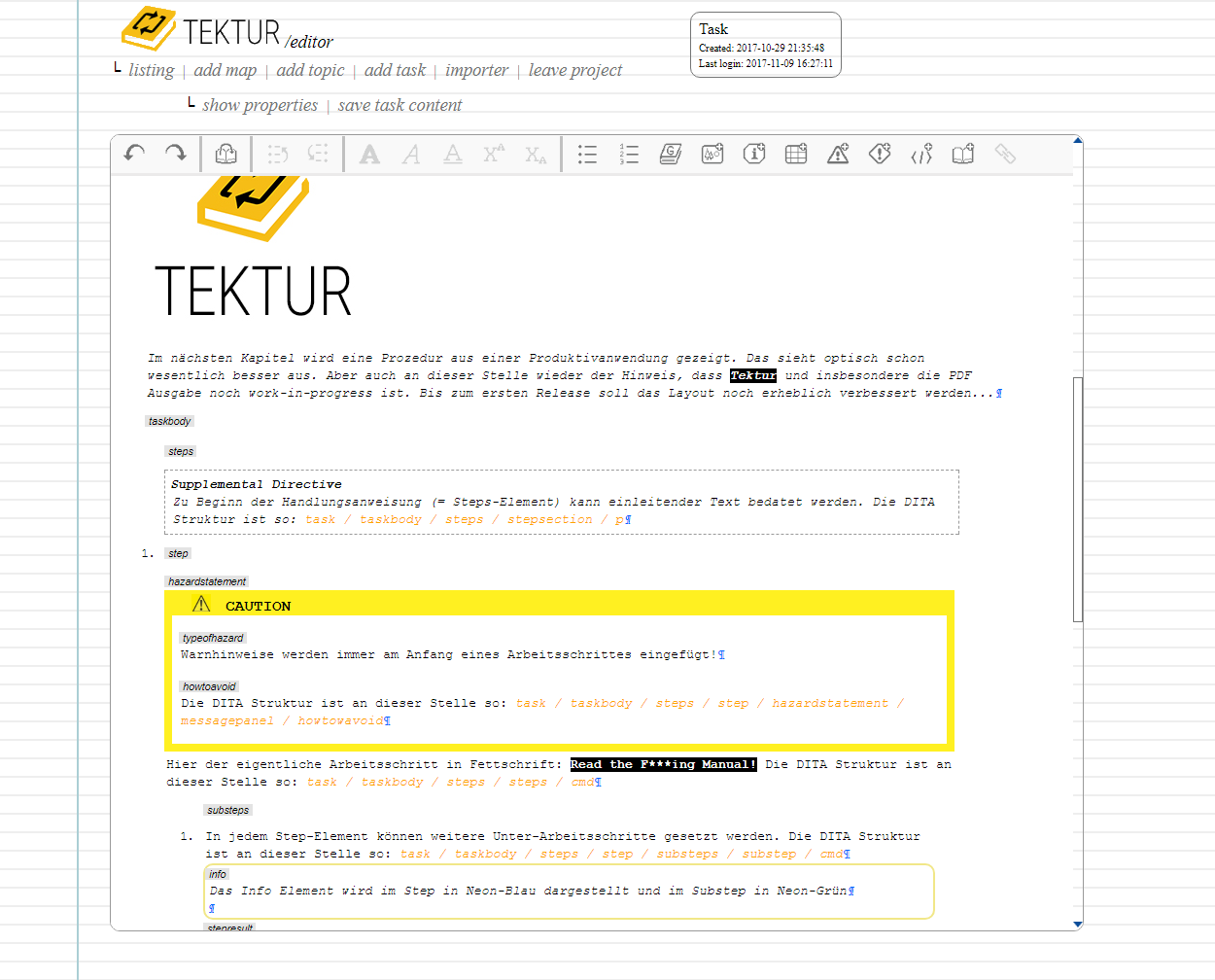
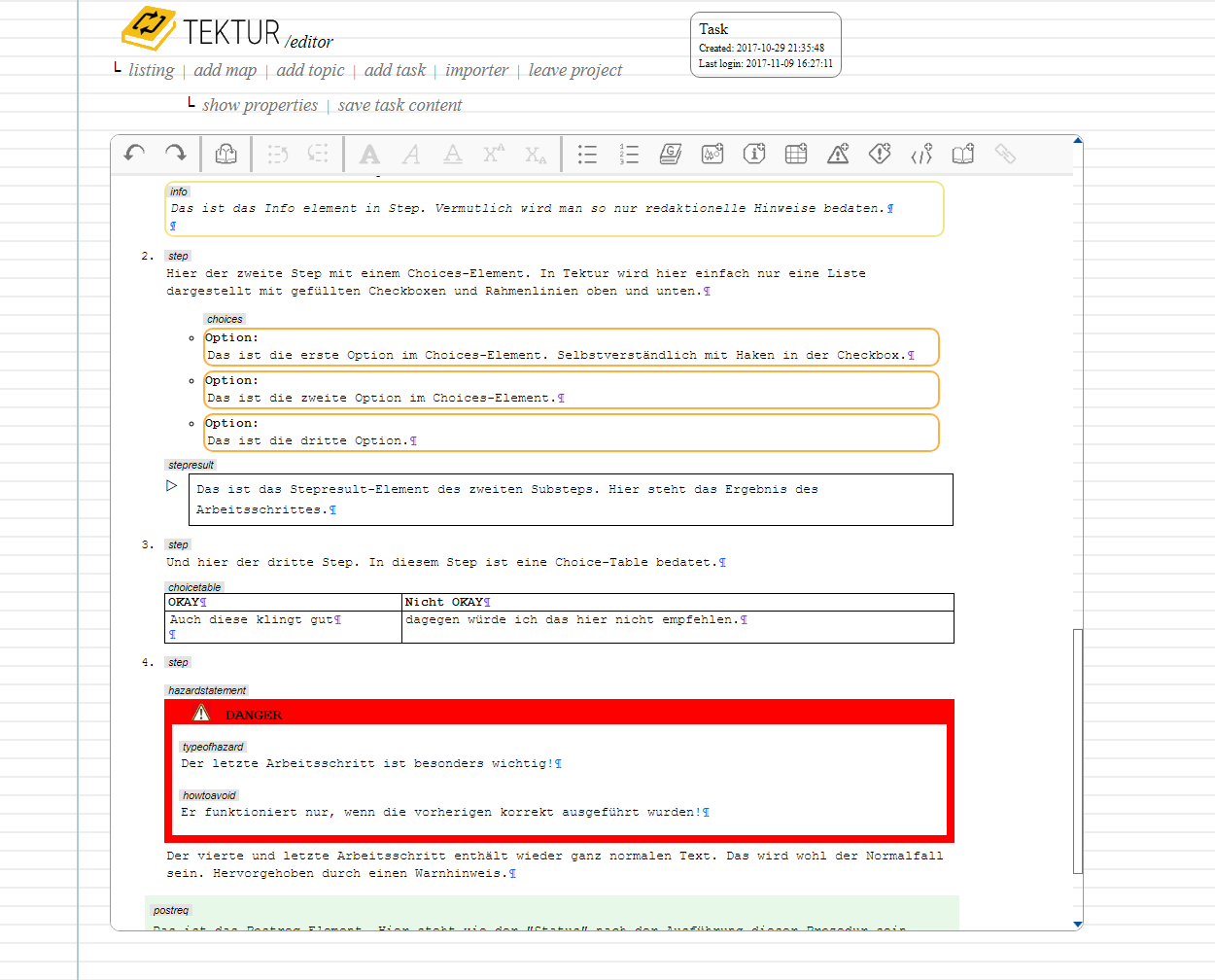
More of a real-world example would look like this:

Editing view:
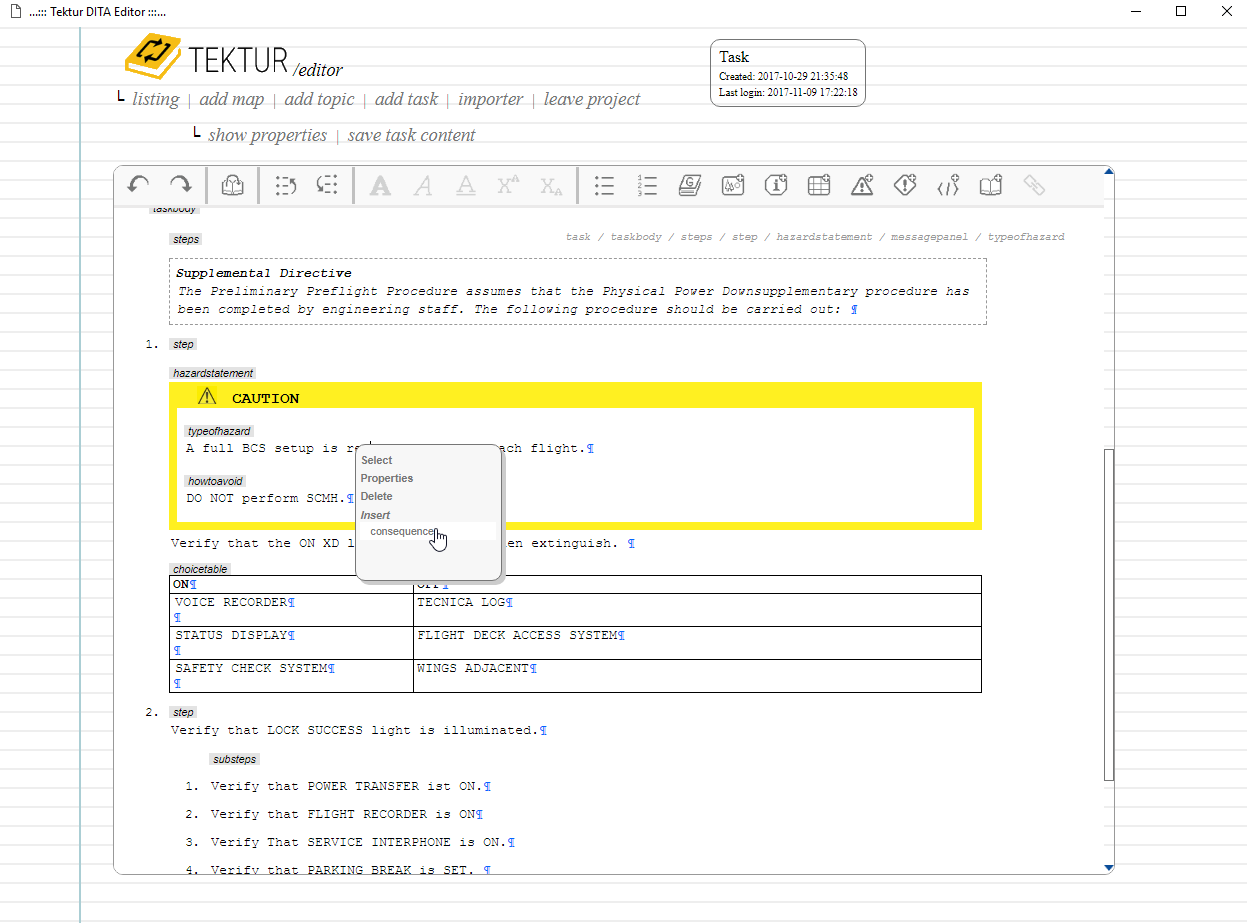
September 21st, 2017
Major Redesign
Brand new design and styles...

August 28th, 2017
Toolbar Icons
The gfx department is working hard on some custom icons for the toolbar of the editor panel...
June 18th, 2017
Icons and other gfx
Just ordered some new custom icons and gfx from a designer-friend. Also spent some money on quality assurance and testing. The editor part is 80% completed; entirely written in JavaScript/NodeJS. Thanks to NW.js it runs both on a website and as a desktop application. Here's a screenshot animation of most recent work:
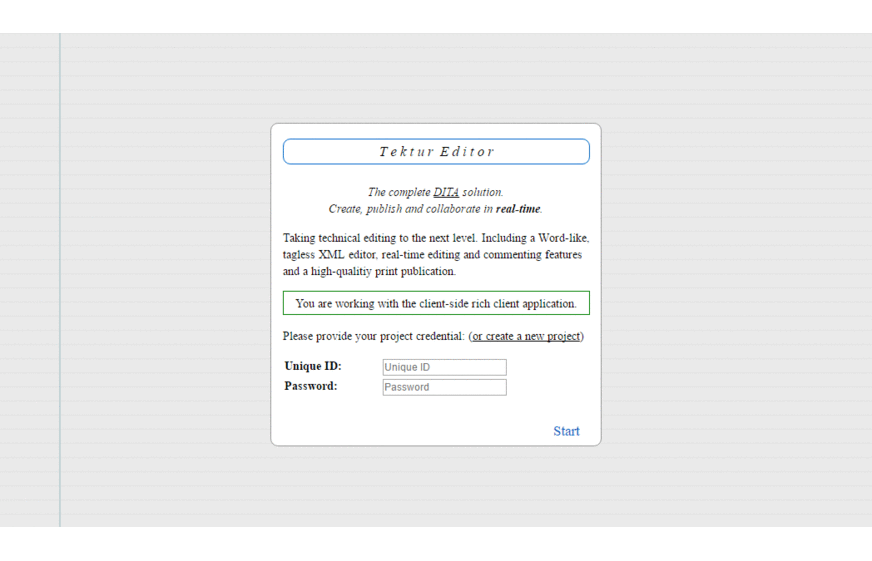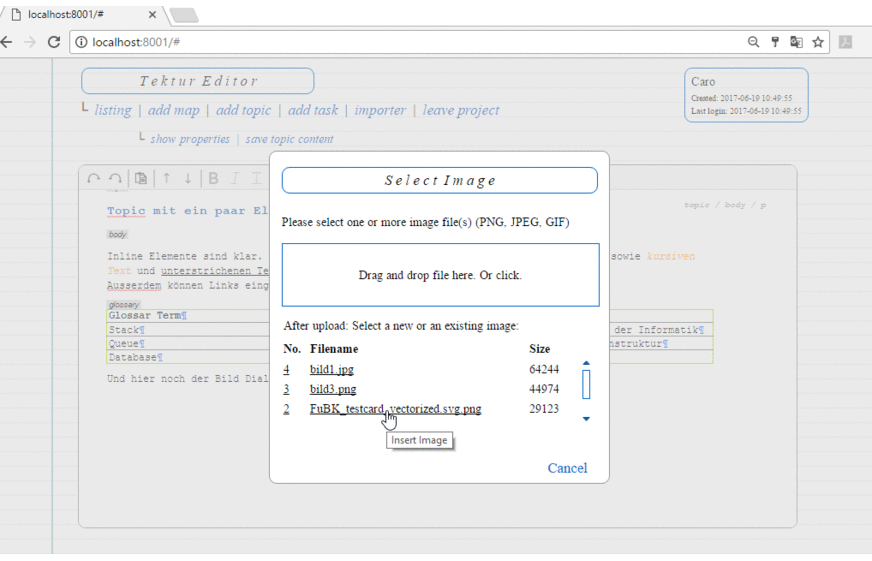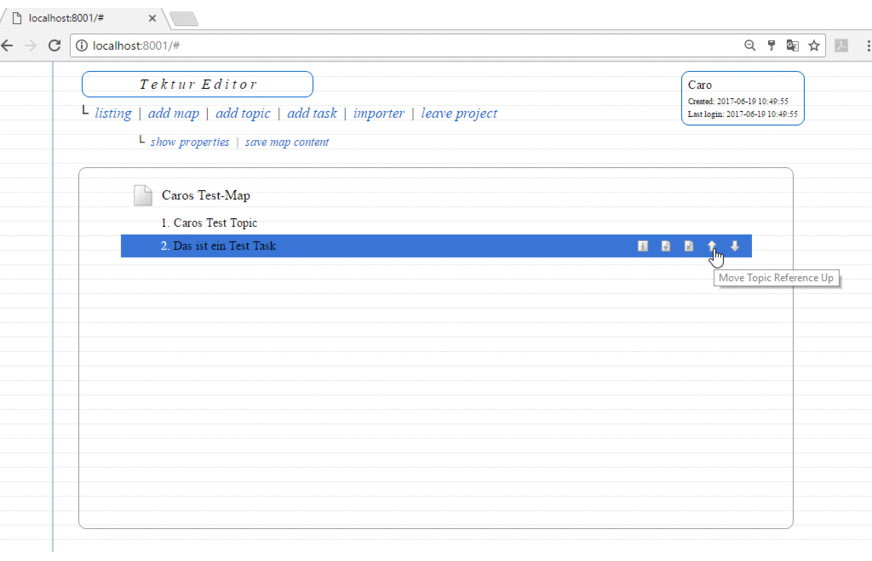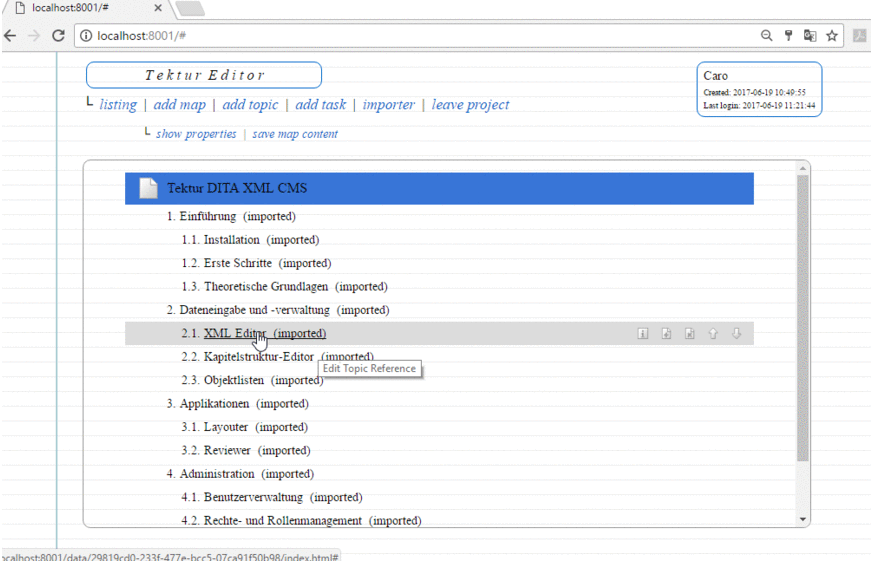
April 22nd, 2017
Tektur Peer-2-Peer Real-Time XML CMS
Actually I was thinking about an easy way to distribute the NodeJS binary and MongoDB together with the Tektur application code.
Finally I came across a different approach to the whole thing. Why not bundle the browser control, the NodeJS binary and the database together as a desktop application with server features?
This is pretty easy using NW.js. It comes with a NodeJS binary and Chromium browser control, that runs on Windows and Mac.
Replaced the MongoDB with TingoDB and voila here is Tektur running in a Desktop window - but still being a server application, that listens on port 8080 for other browsers to connect.
Developing this thought further consequently leads to a new architectural idea:
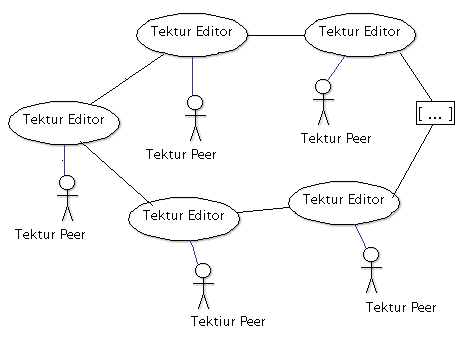
Tektur will be a server-less peer-to-peer system.
Each user brings her own disk space and computing power, making the system very scalable and secure.
Topics that were created by user XYZ will stay on the computer of XYZ. Well, that's the idea, long term.
April 16th, 2017
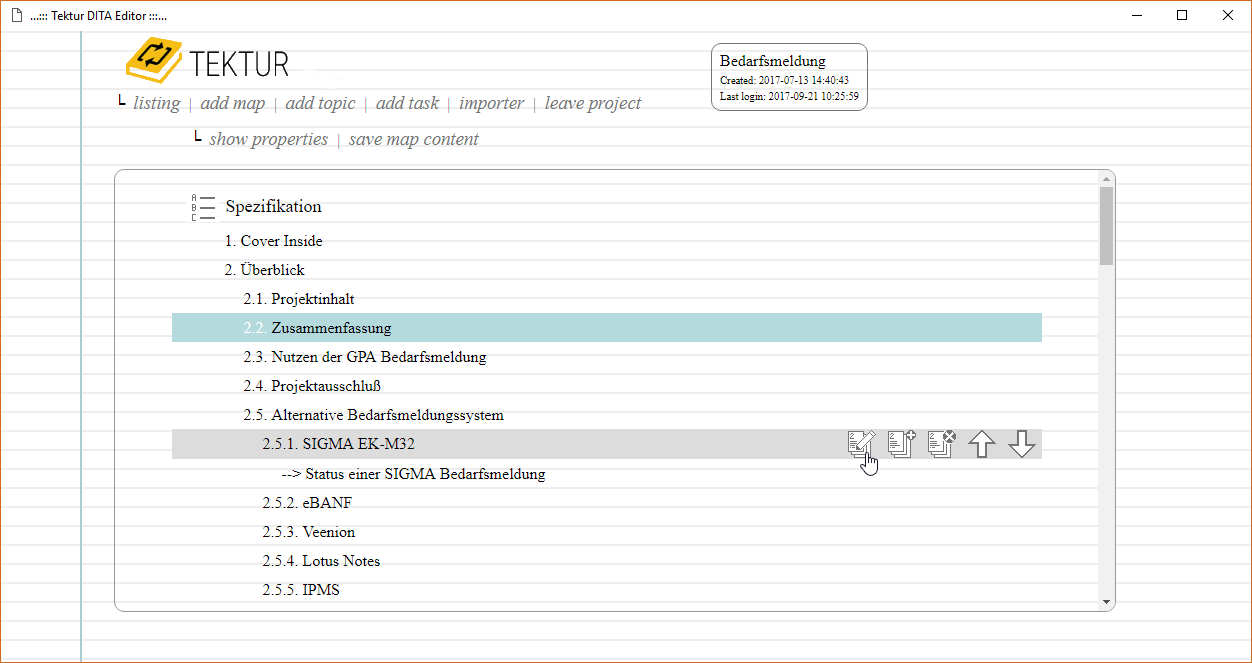
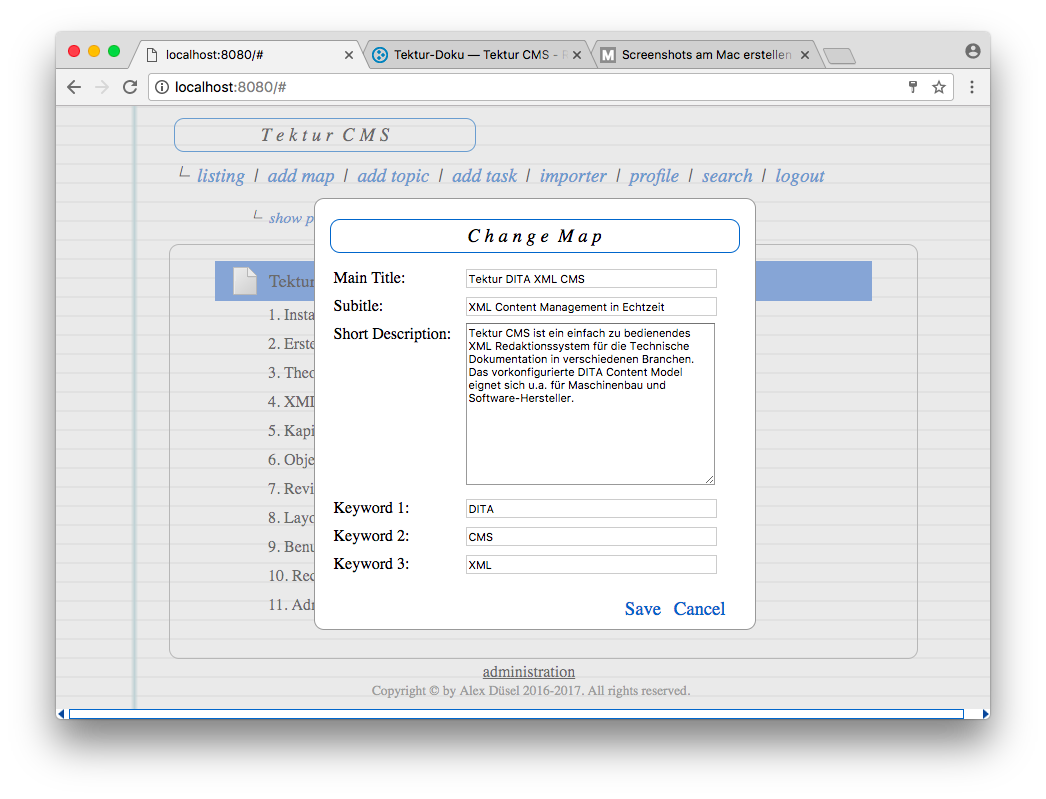
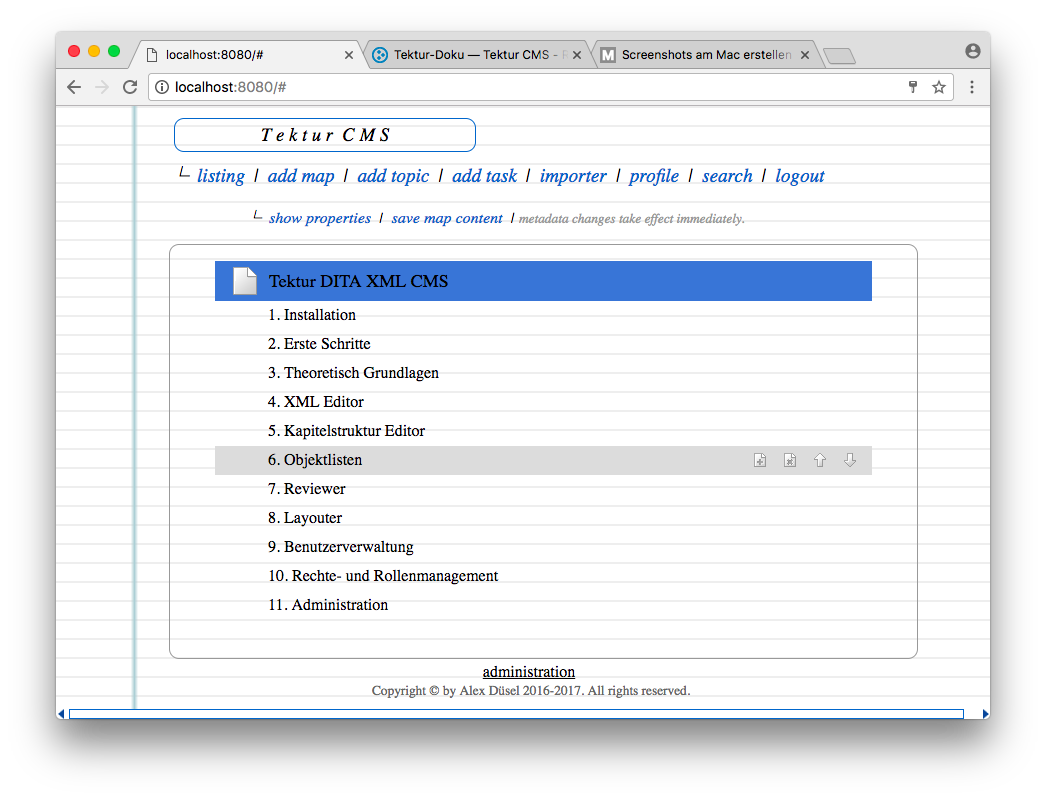
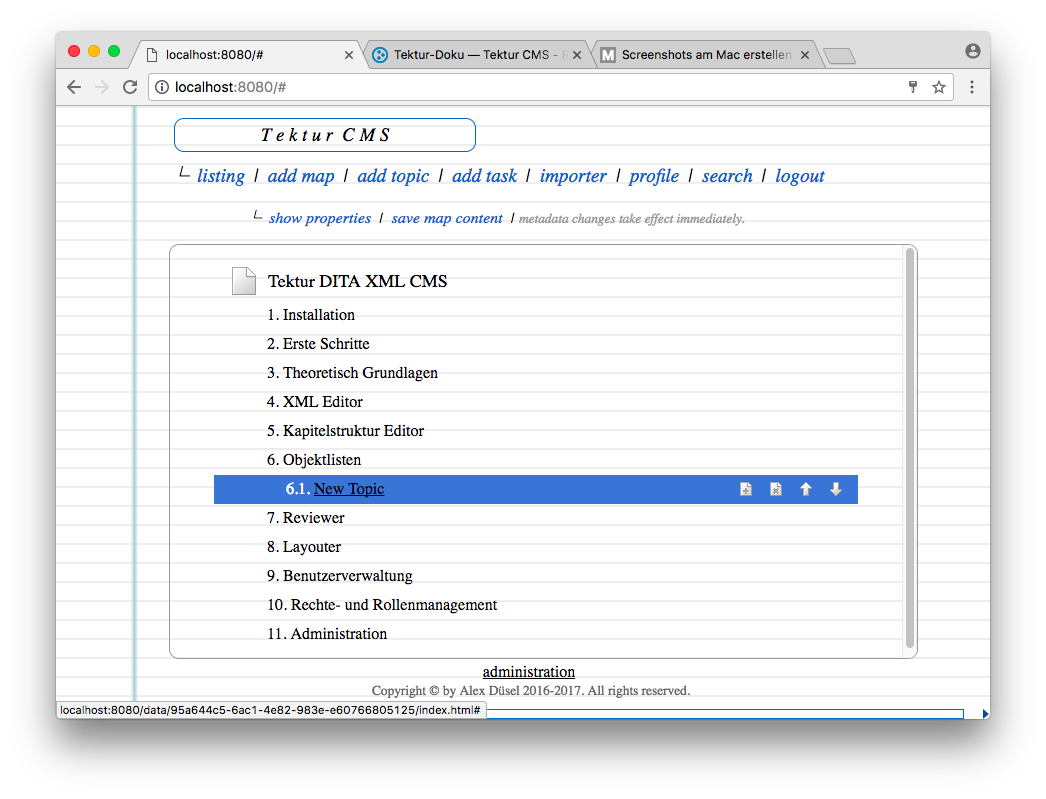
Maps Editor
Started implementing the DITA maps editor. I am reusing a control which I wrote for the UWE project some years ago� basically some custom Javascript that sits on top of the well crafted jQuery TreeTable plugin.
The user can arrange the DITA map by drag 'n drop / buttons for inserting, deleting and moving the topics.
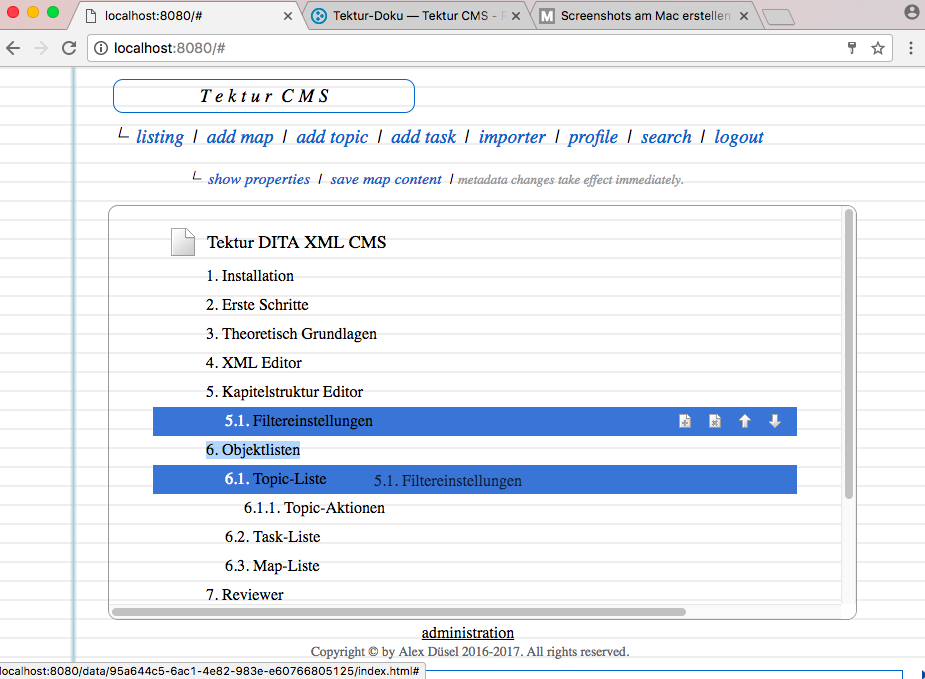
A click on the topic/map titles shows a popup dialog with further options. See some screenshots below:
March 25th, 2017
RTFM - Read The F*** ahem Fine Manual
Started a documentation project for Tektur www.stylesheet-entwicklung.de (German speaking).
While editing the documentation site using Plone as CMS I realized once more that the integrated editor of Tektur is far better than TinyMCE, CKEditor and the like.
For example It is a nightmare to reorder complex list items with TinyMCE using copy and paste. You'll end up editing HTML tags in the source view. This is definitely not user friendly...
February 18th, 2017
Table Input
Tektur features CALS tables, which are more complex than HTML tables.
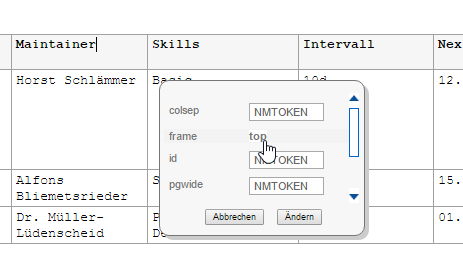
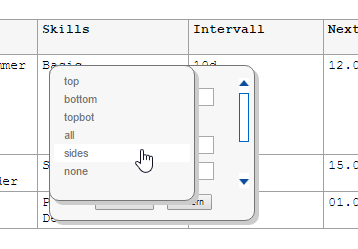
Only a subset of CALS attributes can be rendered in the editor. Other properties have effect only in the PDF output, such as @frame:
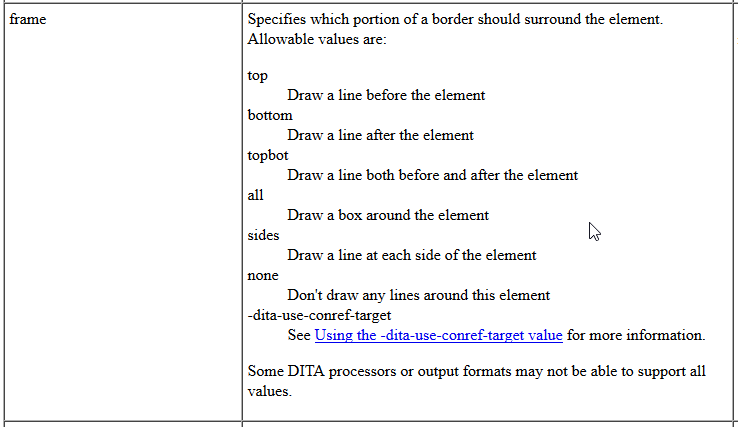
Also @pgwide that allows for setting the table page-wide or column-wide.

CALS tables may suffer from an erroneous markup constellation, due to their complex nature.
Therefore we check each user input. If the input breaks the table geometry, the current action is automatically undone, leaving the table in a consistent state.
The "tablefixer algorithm", which I designed a while ago (scroll down and see my post at August 17th, 2014) was reused in order to implement this feature.
Following some screenshots:
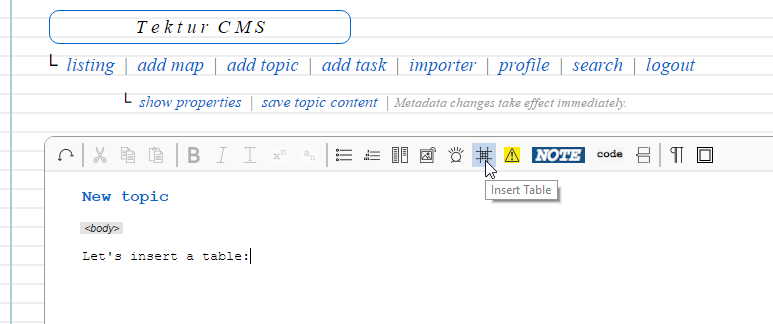
Insert a table on the next allowed position by pressing the table button in the toolbar. (Note that, according to the DITA content model, there are several restrictions when inserting a table)
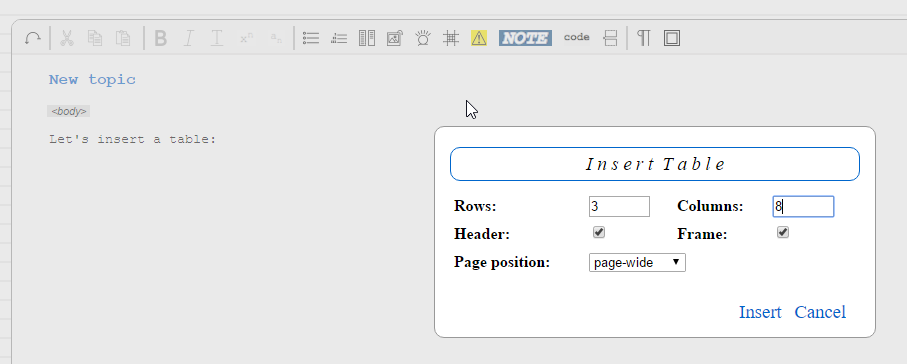
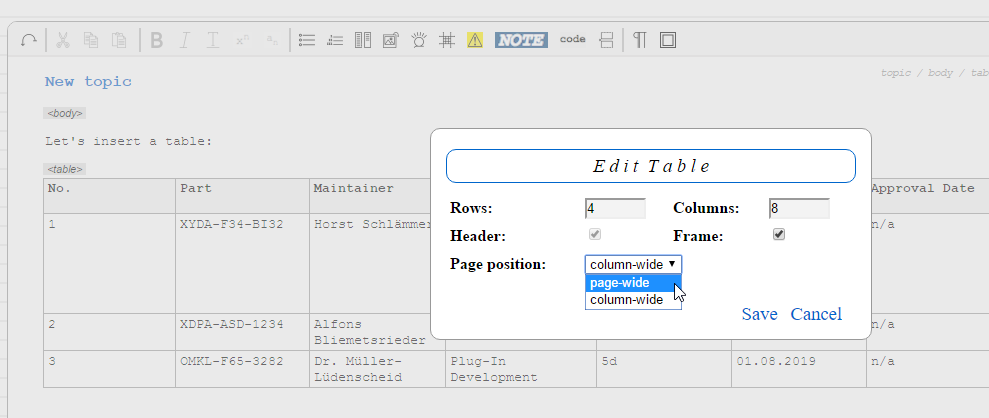
Edit important properties in the "Insert Table" dialog...
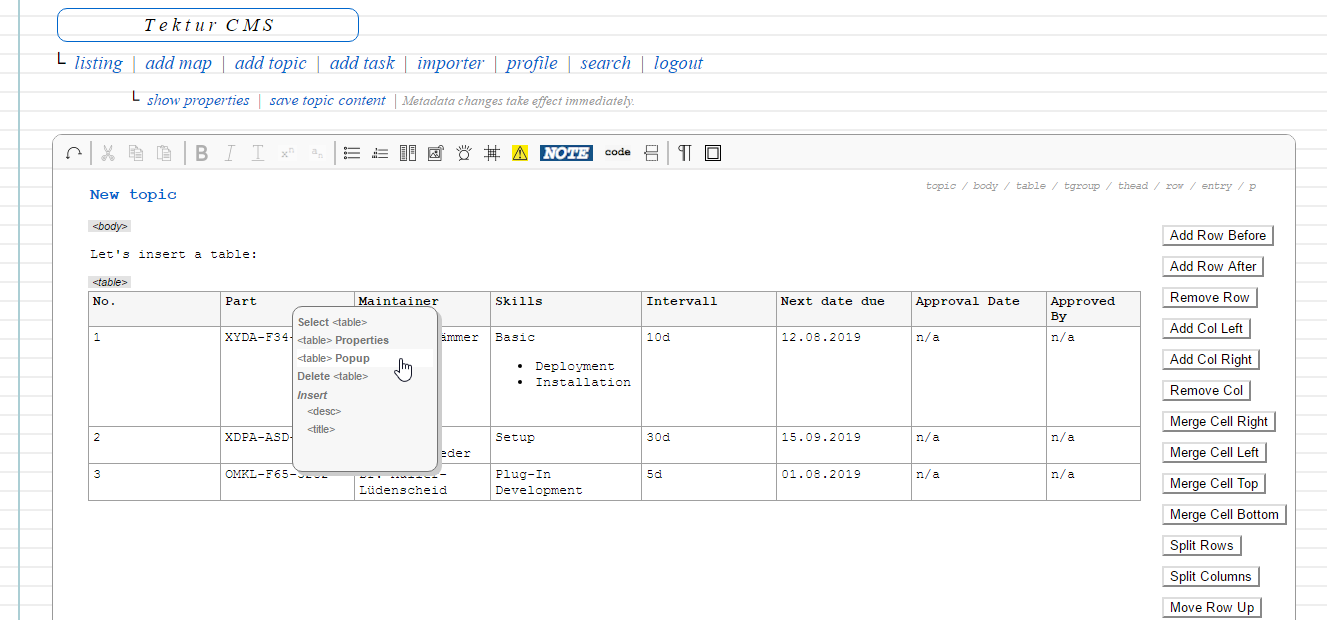
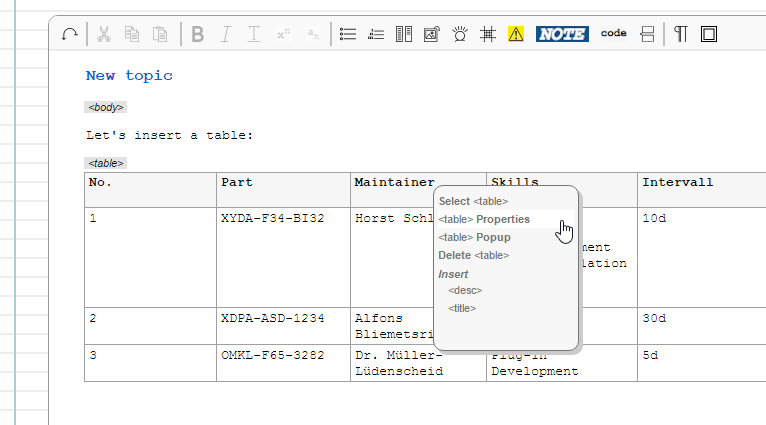
A right-click on any place in the table area will bring up the standard context menu with a special entry "<table> Popup". A click on this entry will show the "Edit Table" dialog.
Expert users may also use the standard properties dialog in order to modify special CALS attributes:
For example one could set a custom frame option for the PDF output:
and set a desription for this table:
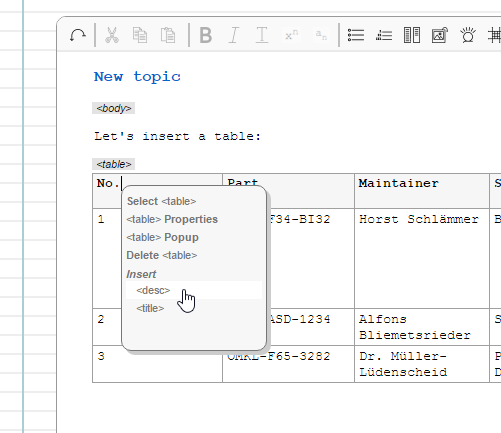
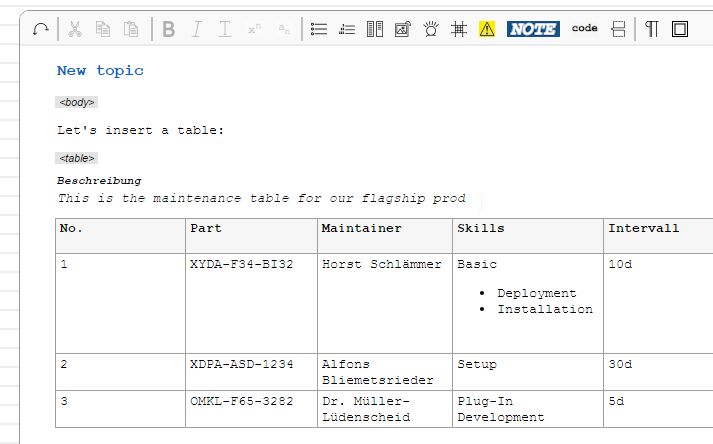
That's all: Tables are feature-complete, yeah :-]
Oh wait: There is something left to do. I'd like to set the width of each table cell using drag'n drop. Currently I am experimenting with a JS library colResizable which works just fine, but still having some issues with copy 'n paste and spanned columns...
February 4th, 2017
The Awesome User Graph
Rights and roles are fully configurable. Custom roles may be:
-
An Author is the owner of a book and inital editor.
-
Co-Authors will be invited by Authors to write certain chapters or sections.
-
Internal-Reviewers will work in the same department or company. They start commenting on text paragraphs and other elements of a certain topic in a "reviewing phase".
-
Internal-Approvers will check the book, single chapters or topics. They will accept or reject the book for external review.
-
External-Reviewers probabely work at the customer's site. They will add change requests and/or corrections.
-
External-Approvers: They will approve the book or specification if it fullfills the customer's expectations.
-
Quality-Managers check the book if it is okay with the quality standards of the company.
-
Compliance-Managers: They check the book if it is okay with legal and ethical standards.
-
Responsible-Managers: Well, these people are the bosses.
When users of Tektur work on different books with different roles it can get rather complex. Fortunately we can visualize relationships as a graph:
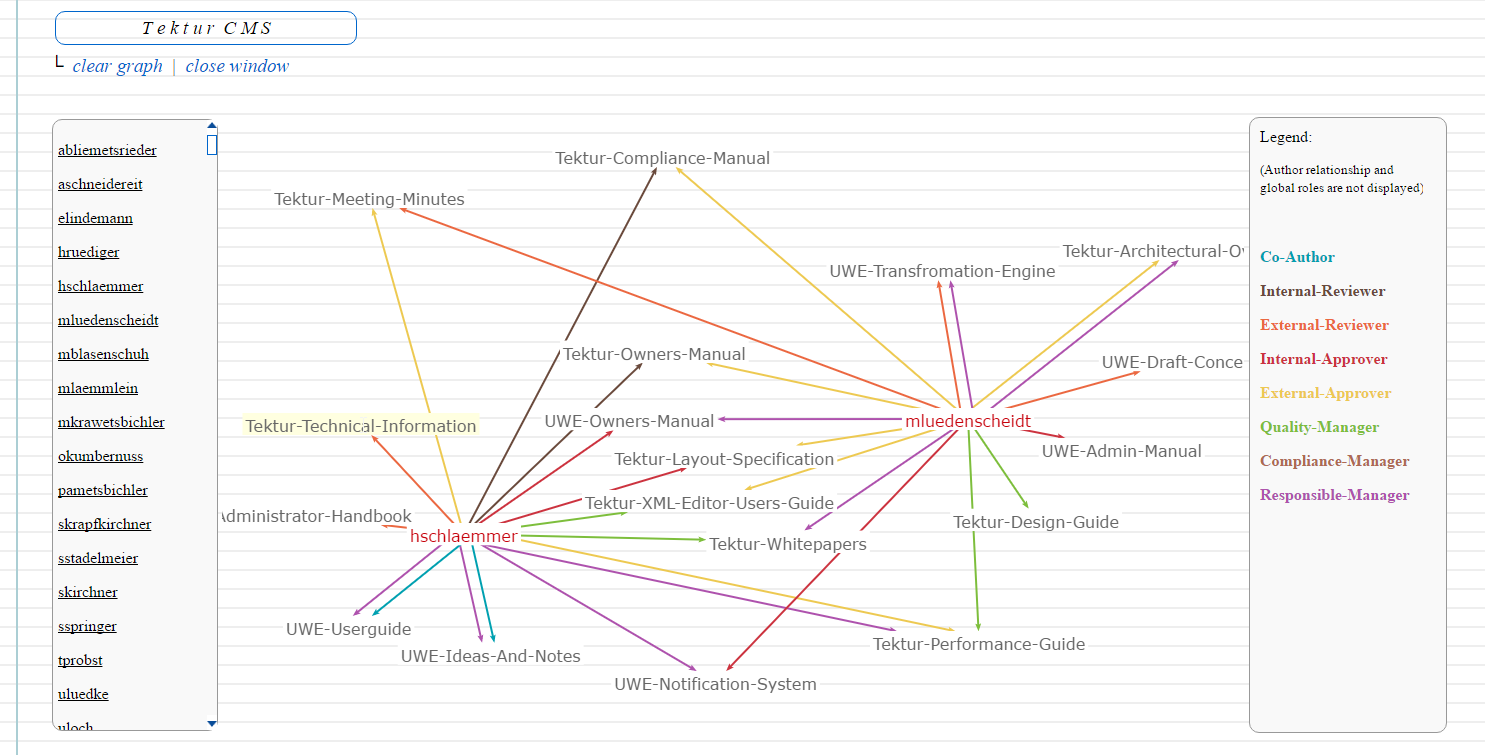
This fancy graph (which is not a real-world example!) has been implemented using the fine Springy.js library (A force directed graph layout algorithm in JavaScript). If you click on a username the graph will be expanded with the user's role information.
Basically the configuration of the system, which can be edited using a HTML5 form, is transformed to XML data, that is transformed to JSON data, which finally acts as the input for the Springy library. So easy!
January 29th, 2017
Synchronized Profile Data with Django Admin
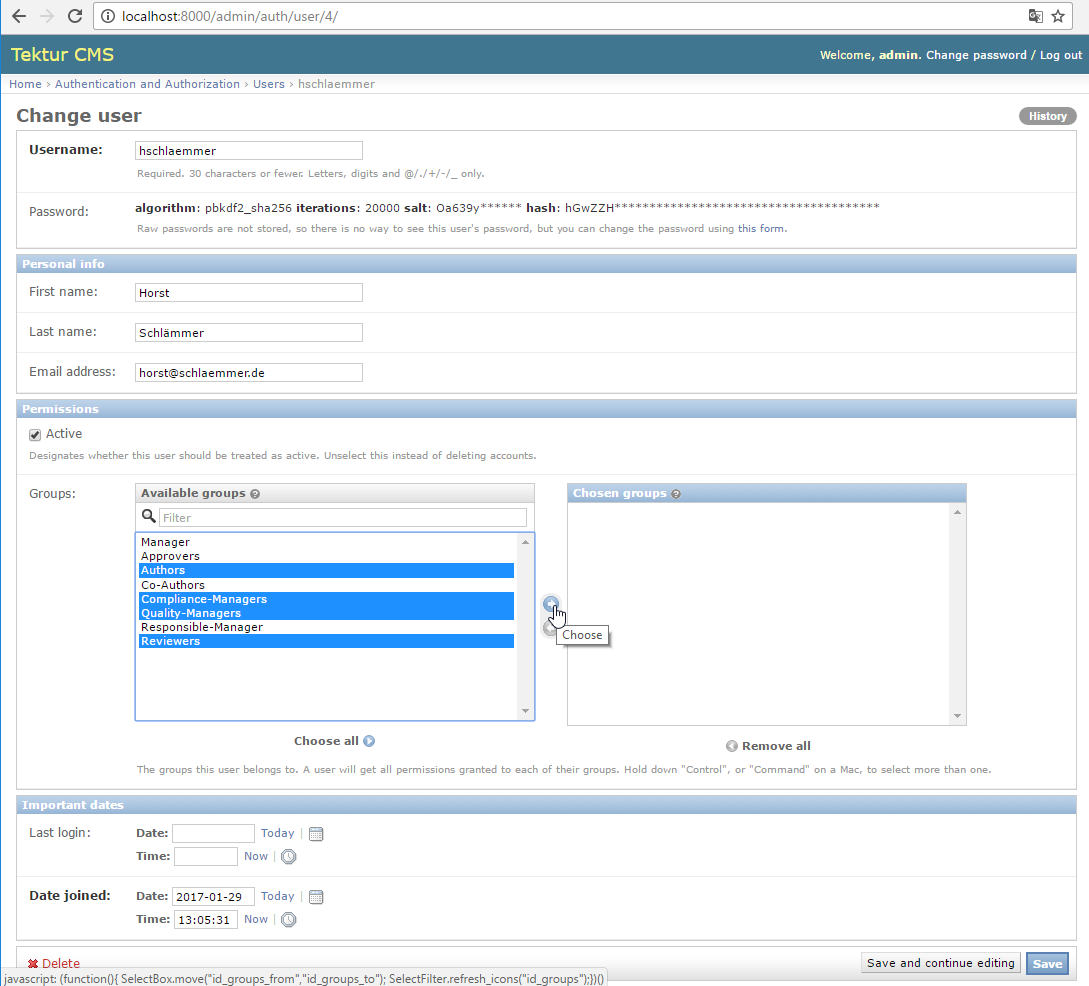
Django comes with an excellent Admin interface out-of-the-box. Today I have been synchronizing the registration of new users:
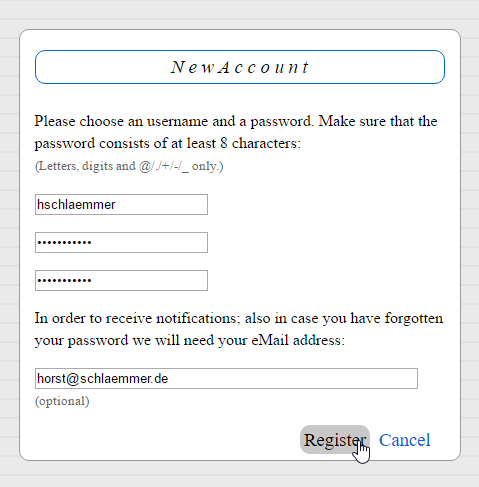
The Profile dialog may be checked and changed at any time:
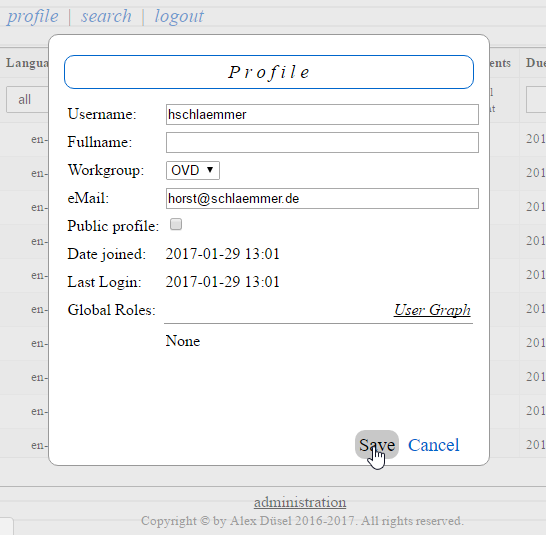
The administrators of Tektur may change further options in the Django Admin interface:
The NodeJS view will be updated with the changes in real-time. Also note the link "User Graph":
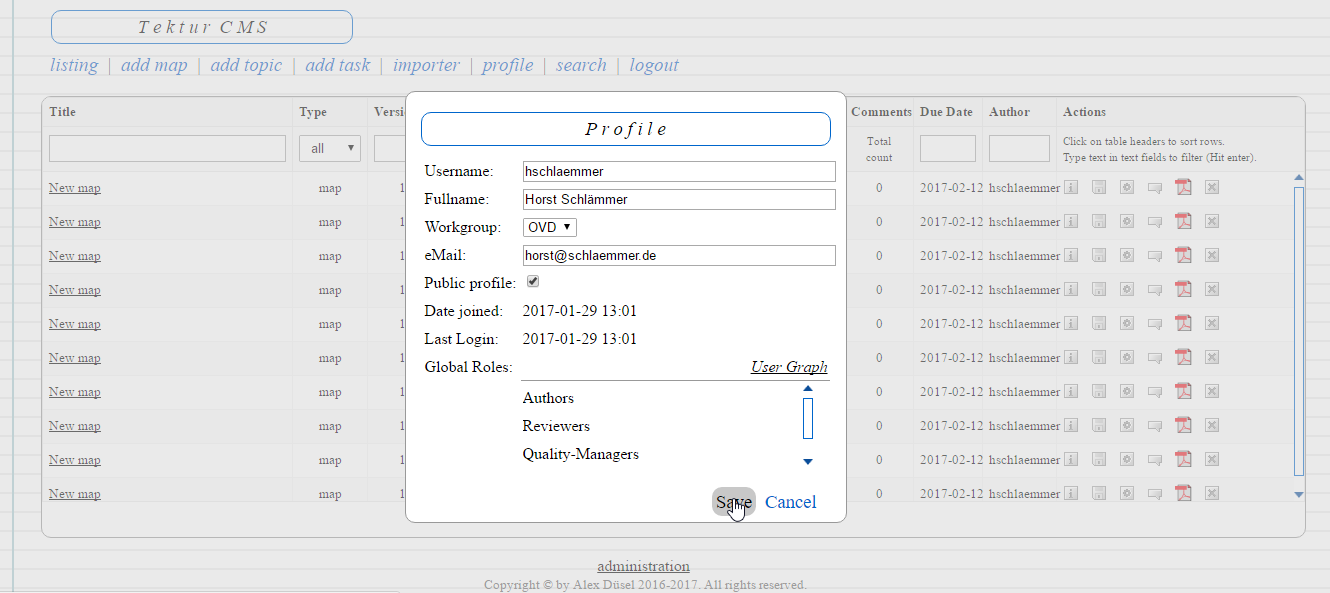
In addition to the global roles which apply to every book in the system, the user may also be assigned to specific topics or maps. This complex relationship will be implemented using a graph (Coming soon).
January 14th, 2017
Topic Listing is Feature-Complete
Just finished work on the topics listing. I am giving you a short idea about the "business plan". The first release of Tektur, which is scheduled by the end of 2018, will be a "teaser". It will feature the basic functionality:
-
Different groups can create and collaboratively edit a DITA document.
-
Rights/roles/actions can be assigned on a fine-grained level.
-
Other groups can be invited to work as Co-Authors.
-
All information objects can be reviewed, approved and rejected by responsible groups.
-
Important output formats such as PDF can be created on-the-fly.
-
Comments, notifications and messages will be distributed in real-time.
The system will be put online with a large set of demo documents. I will invite some people in the techdoc industry for beta-testing...
Here are some screenshots of most recent work:
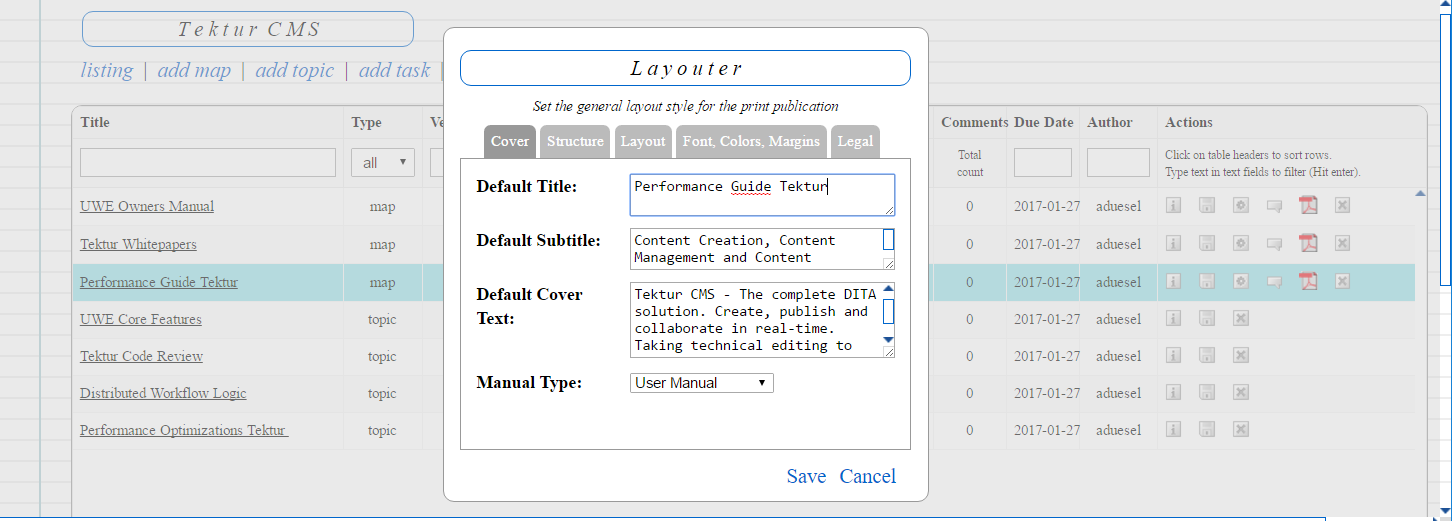
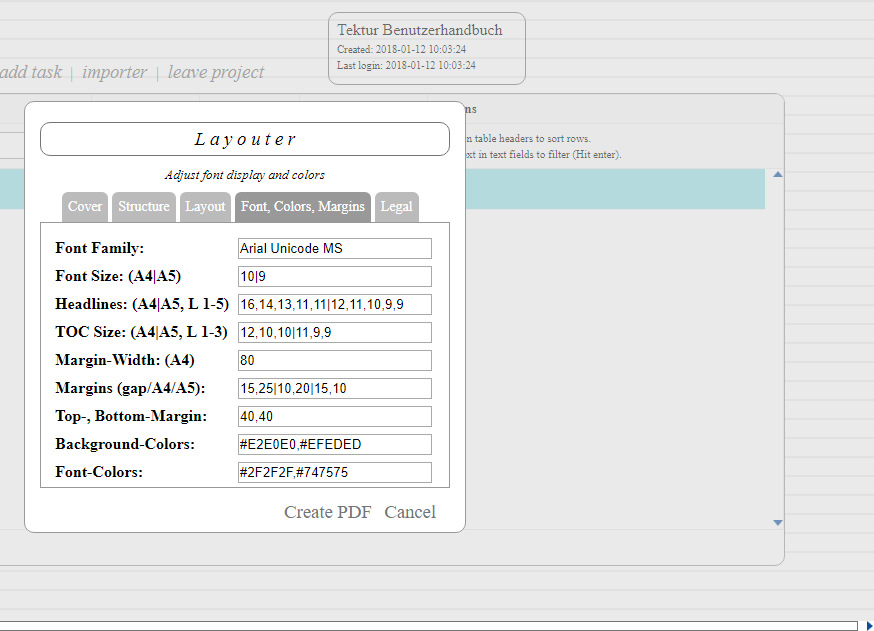
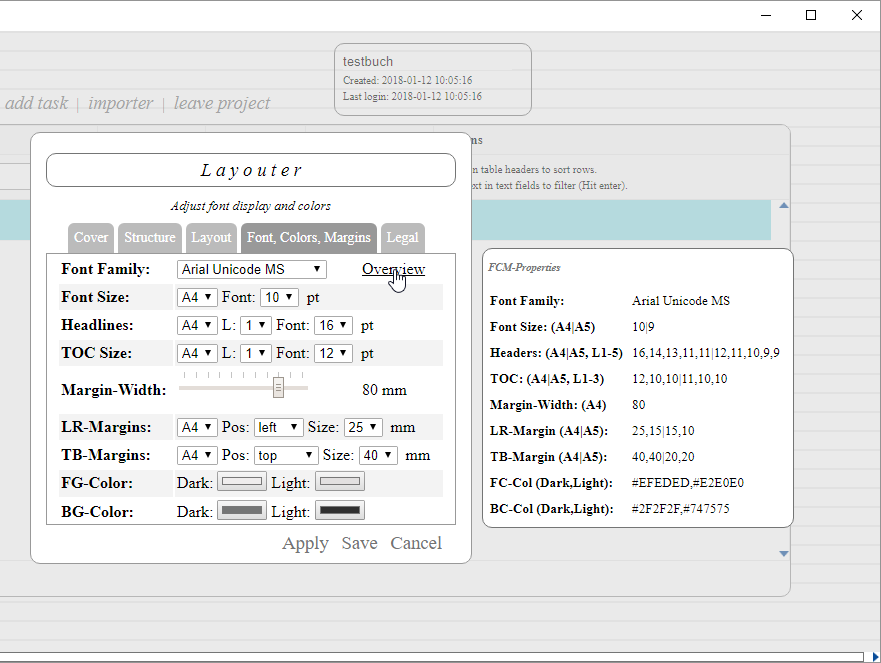
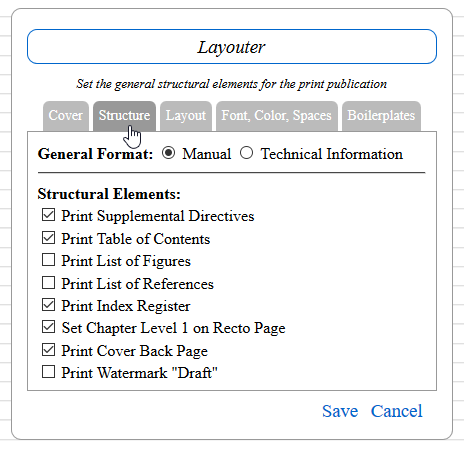
Major design decision: The Layouter dialog is now connected to each element in the listing. Thus each element may be styled individually.
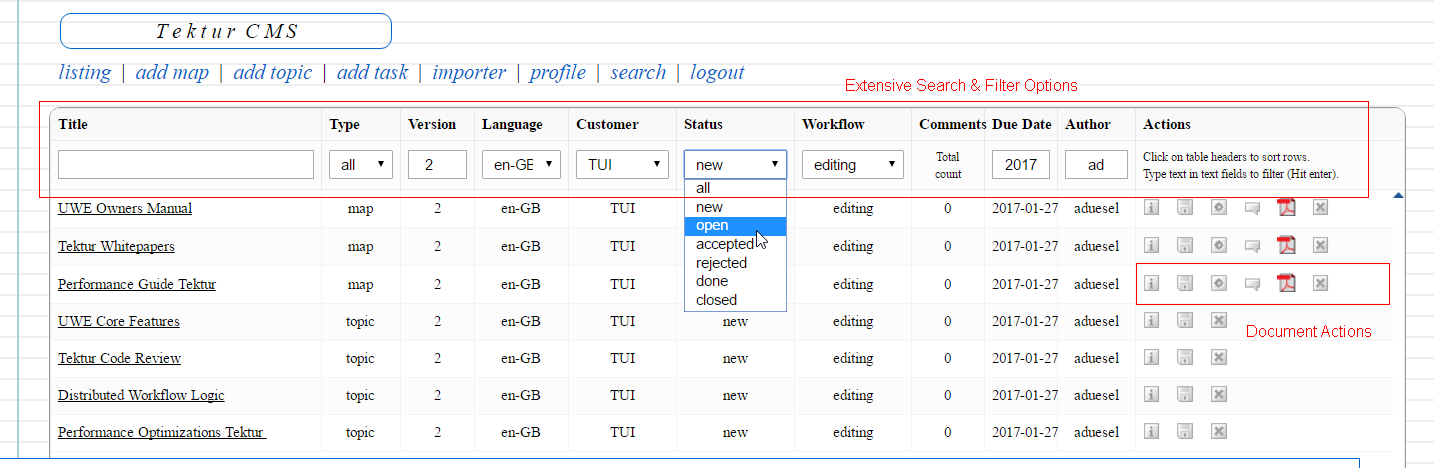
Extensive search and filter options are located in the table header. The list will be updated in milliseconds. Filter options are persisted while changing the HTML5 single-page views. Document actions are as follows:
-
Show more information.
-
Export element in DITA format.
-
Show Layouter dialog.
-
Show element in Reviewer.
-
Generate PDF output.
-
Generate RTF (=Word) output.
-
Delete element.
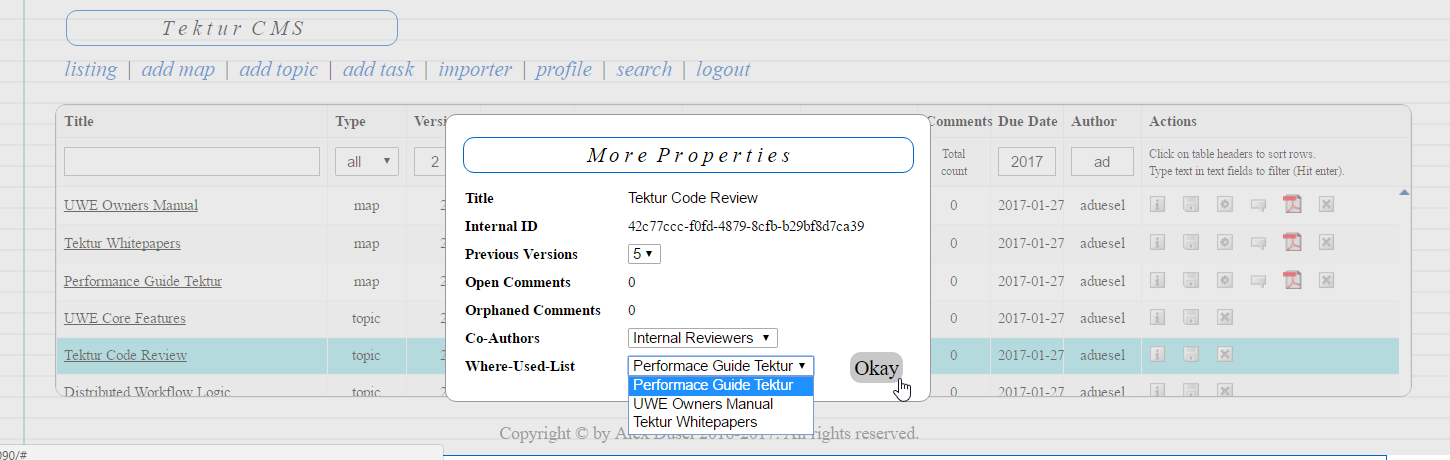
The popup dialog for the more info box will also show all DITA maps where this topic is used. The user can click on a link and will be redirected to the corresponding map.
January 4th, 2017
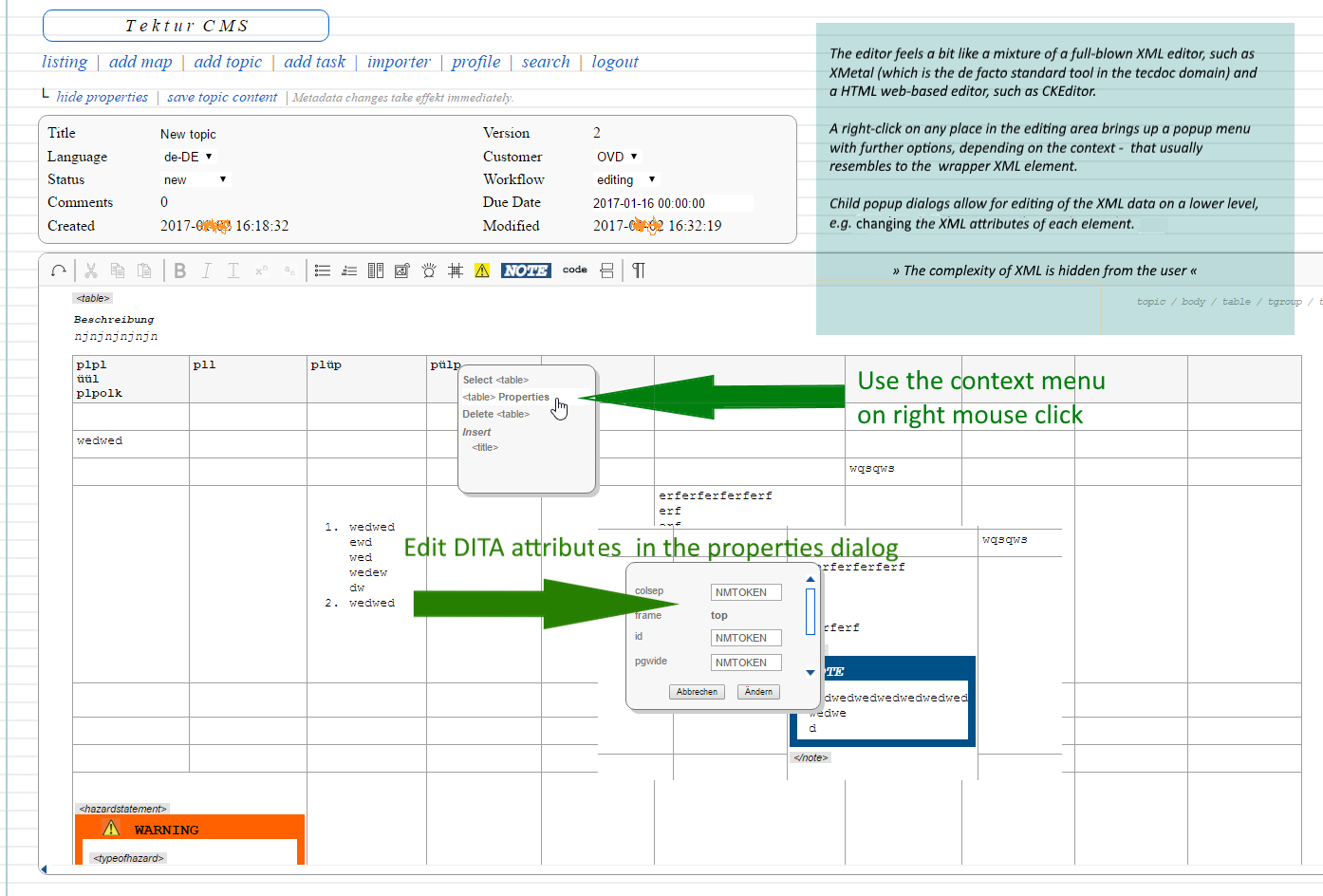
Working with the XML editor
December 26th, 2016
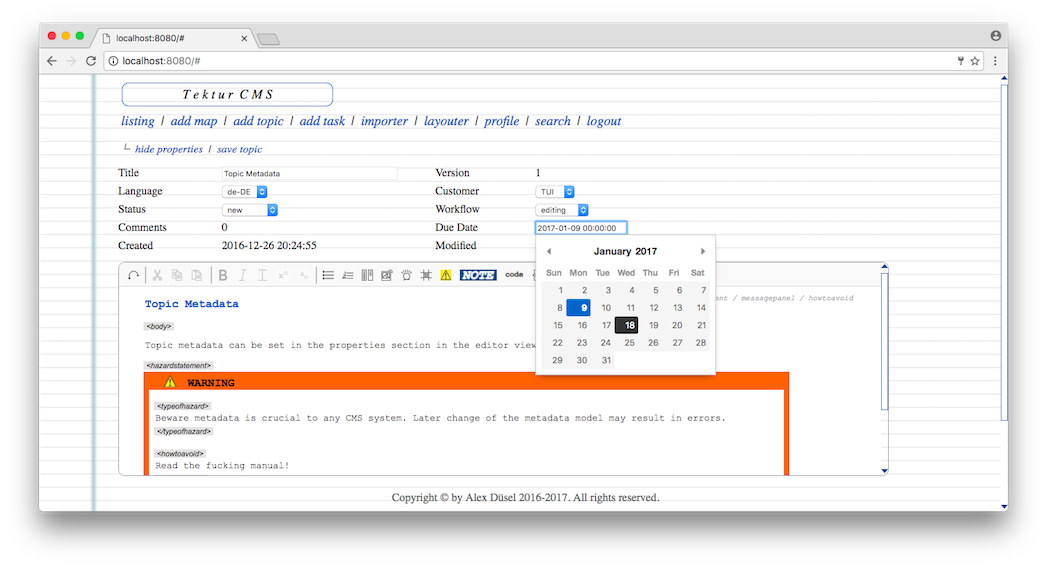
Topic metadata
Added some slidable metadata input fields to the editor view (Note: The datepicker widget is implemented using Pickaday JS library).
December 4th, 2016
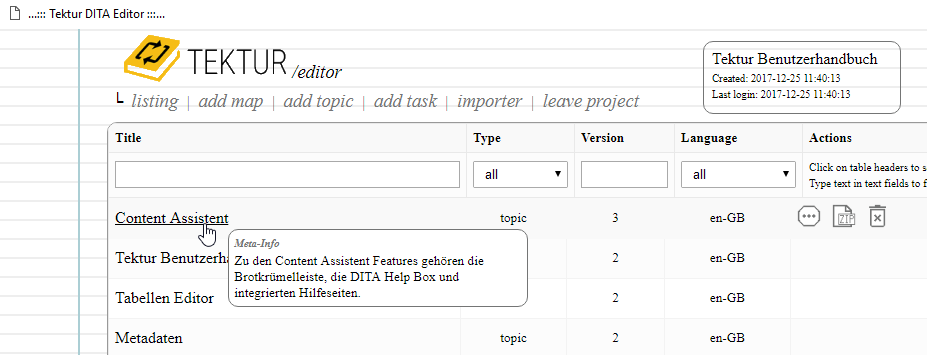
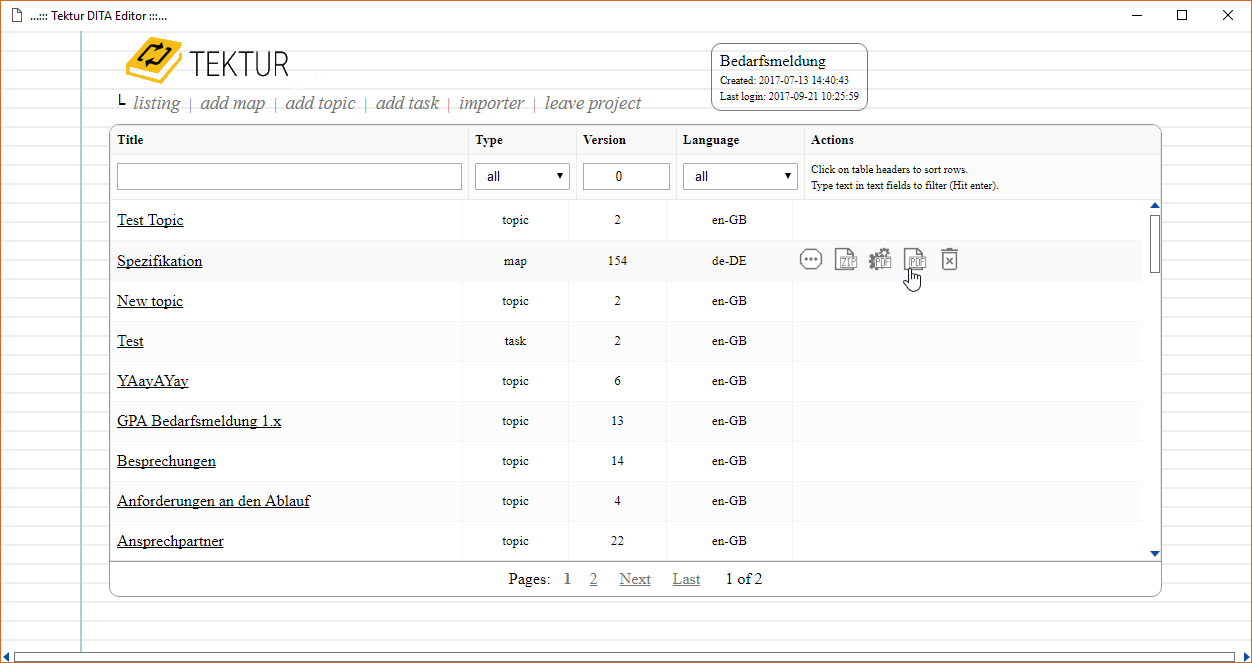
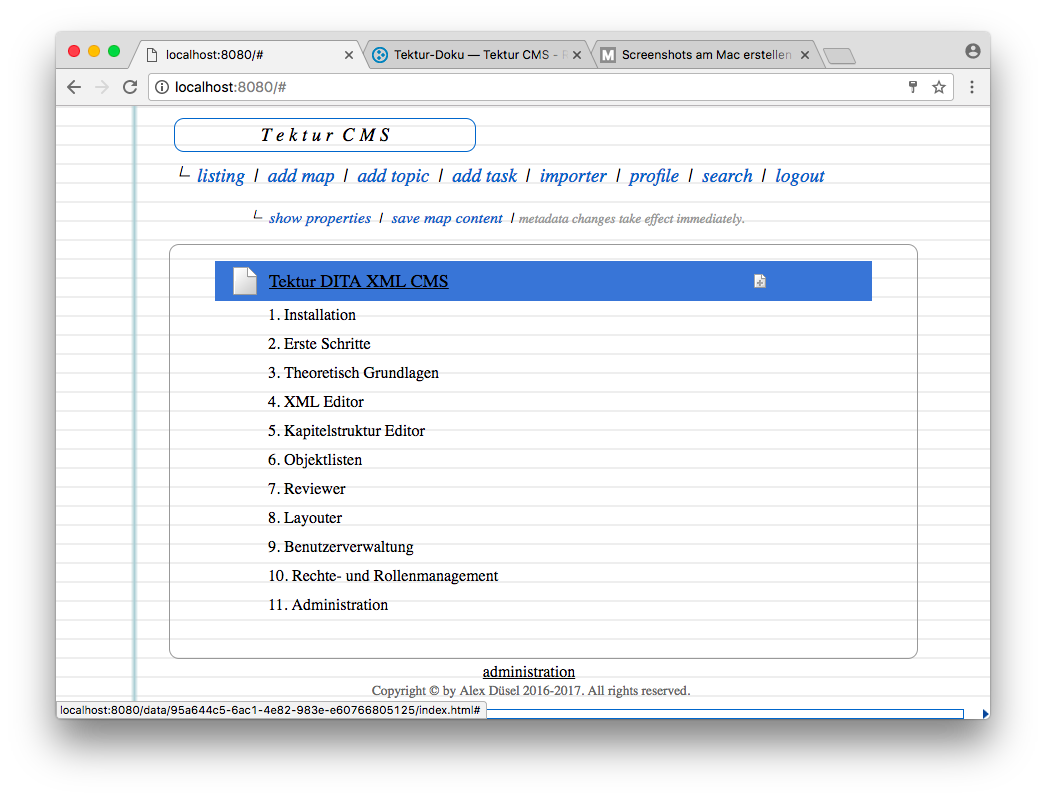
The topics listing
Started working on the topics listing. I have been using the fast jsGrid library.
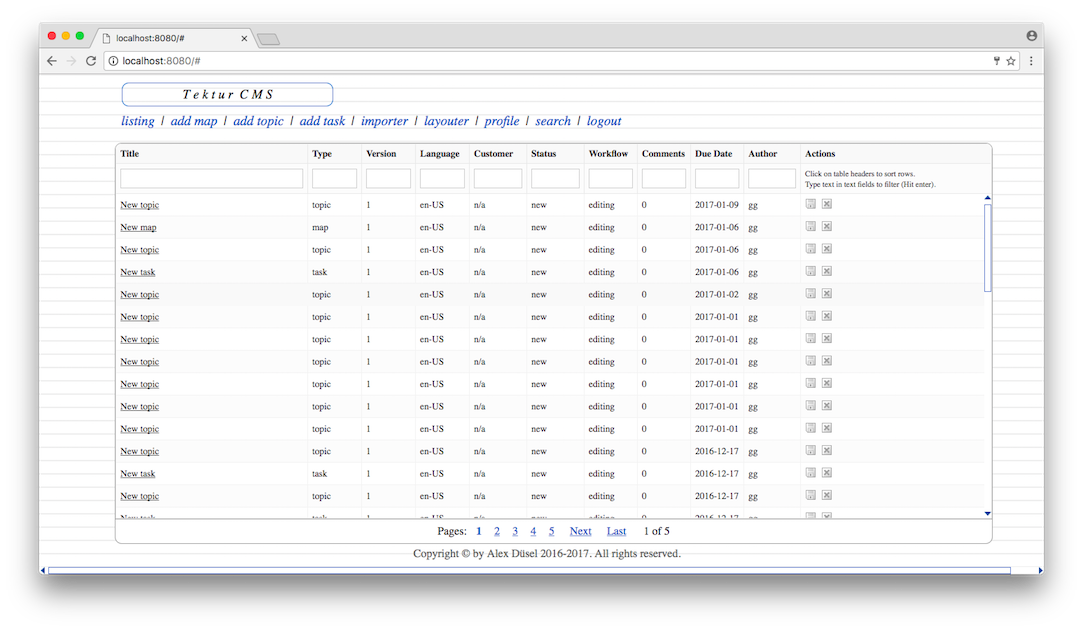
As you can see, there is a lot more space in the column "actions". The first action is "Export the topic as a DITA ZIP file", indicated by the disk icon. Other actions may be:
-
Show in HTML Preview
-
Show in Reviewer Application
-
Generate Print PDF
-
Generate HTML5 Page-Flip Book
-
[...]
-
Go to Properties Page (with more options)
Most of these actions have already been implemented for the UWE project.
December 3rd, 2016
XML related concepts of Tektur
- Modularization
- Generalization
- Validities
- Versioning
- Intelligent References
- Automatic Typesetting
Modularization is one of the key principles of a XML CMS. Whereas ordinary CMS systems let the user organize the content into pages, sections, etc. and do not support the reuse of content on a fine-grained level, Tektur will automatically split up the content into small pieces of information. This allows for maximum reuse.
Also the underlying XML DITA information model allows for semantic tagging of text paragraphs, procedures, tables, figures, and many other customizable semantical elements, that can be searched for, filtered out, linked to and exported.
Generalization is a DITA concept that allows for processing of Tektur content in other DITA system and vice versa. Even if there is customized and taylored data, generalization will add another level of abstraction to the transferred data, making it equal - without information loss.
Validities is a techdoc specific requirement. It boils down to a fine-grained conditional processing of the data. The conditions can be set by the editor and are loosely coupled to the data. Those conditions can be changed at runtime, making conditional processing a flexible approach to increasing product diversification, without changing the actual data but only the configuration of the system.
Versioning is a common feature to all CMS systems. But with a XML CMS it is possible to mark changes on a fine grained level.
That is all changed words, all deleted words and all new words are marked.
Changes can easily be related to users and to versions. These changes can be listed, filtered out or processed further. For example it is easy to mark TOC entries when there is a change somewhere in a subchapter.
References to other text parts on different pages is a common feature in print publications and in electronic formats.
This functionality is commonly known as hyperlinking. With a XML CMS hyperlinks can target all elements, e.g. paragraphs, figures, tables, chapters, ... and can be put on any place in the content.
The text of the hyperlink can dynamically be generated by the system, together with the correct page number, properly set for different languages and with different boilerplate text.
But there is a difficulty with this approach. The correct version of the target text part must be determined. As you can guess this is tricky since the modularization and versioning features of Tektur.
Automatic Typesetting is an indispensable feature in the field of technical documentation. Custom layout is slow, expensive and often stuck to the data. We could transform HTML input into a PDF. But this is not sufficient.
Here is a simple example:
A list is declared with HTML using <ul> and <li> elements. if you want to have a title to the list, you probabely want to put a paragraph before the list, like so:
<p>This is the list title</p> <ul> <li>First list item</li> <li>This is the seocnd list item</li> </ul>
Having this structure, there is now way of telling the PDF renderer to keep the title of the list together with the list on the same page. A page break would certainly look ugly.
One could say keep a preceding paragraph together with the list. But what if this list does not contain a title? What if the preceding paragraph spans half of the page?
With XML you could declare:
<ul> <title>This is the list title</title> <li>First list item</li> <li>This is the seocnd list item</li> </ul>
Making this structure semantically belong together. Now you can tell the PDF renderer: Keep all <ul> elements together or split on <li> elements, which is a much better automatic typesetting.
November 26th, 2016
Short notes on the workflow logic
The workflow logic of Tektur will be rather simple.
It is just XML data that holds information on who will have the permission to perform certain actions on the information objects of the system, which are maps, topics, tasks, images, comments, messages, notifications, and queues.
Actions may be: view, add, edit, remove, comment, accept, reject, open, postpone, finish, access and sendTo.
Users can be added to groups, e.g. authors, reviewers, approvers, managers... Each group will have its own xml configuration and its own list of work queues.
Transition of workflow steps will be done by switching the active work queue for group XYZ and sending information objects to queues.
Here is a sketch:
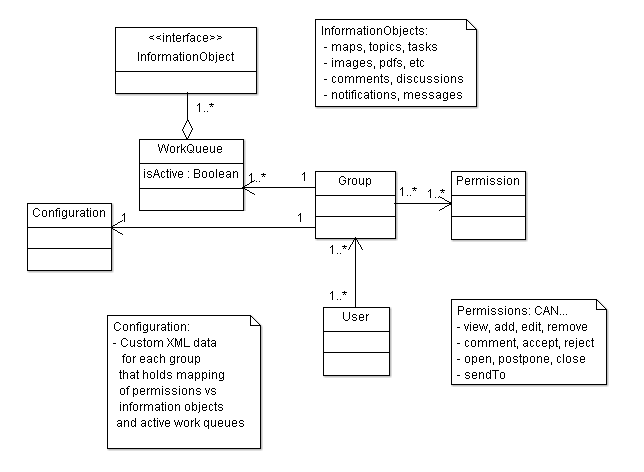
The XML configuration will internally be mapped to JSON that is stored in the MongoDB. Since this configuration has to be looked up very often, that is each time an information object model is queried for, but will be updated only here and then, this approach should be sufficient.
There won't be too much object orientation in the code since OO tends to slow down systems, especially in scripting languages...
November 19th, 2016
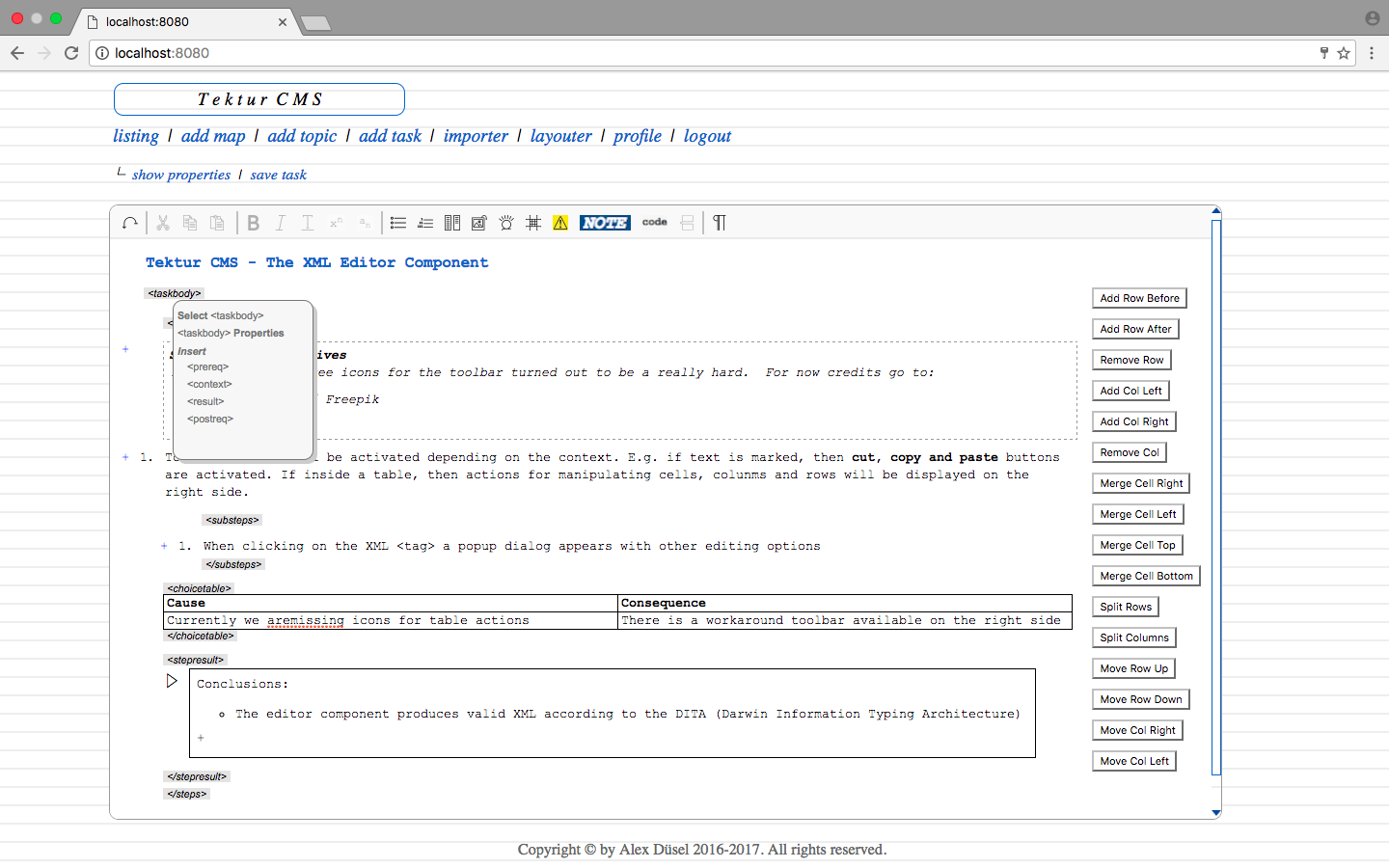
More about the XML editor
Free toolbar icons are hard to find. Looking forward to receiving better icons from a designer friend soon.
November 13th, 2016
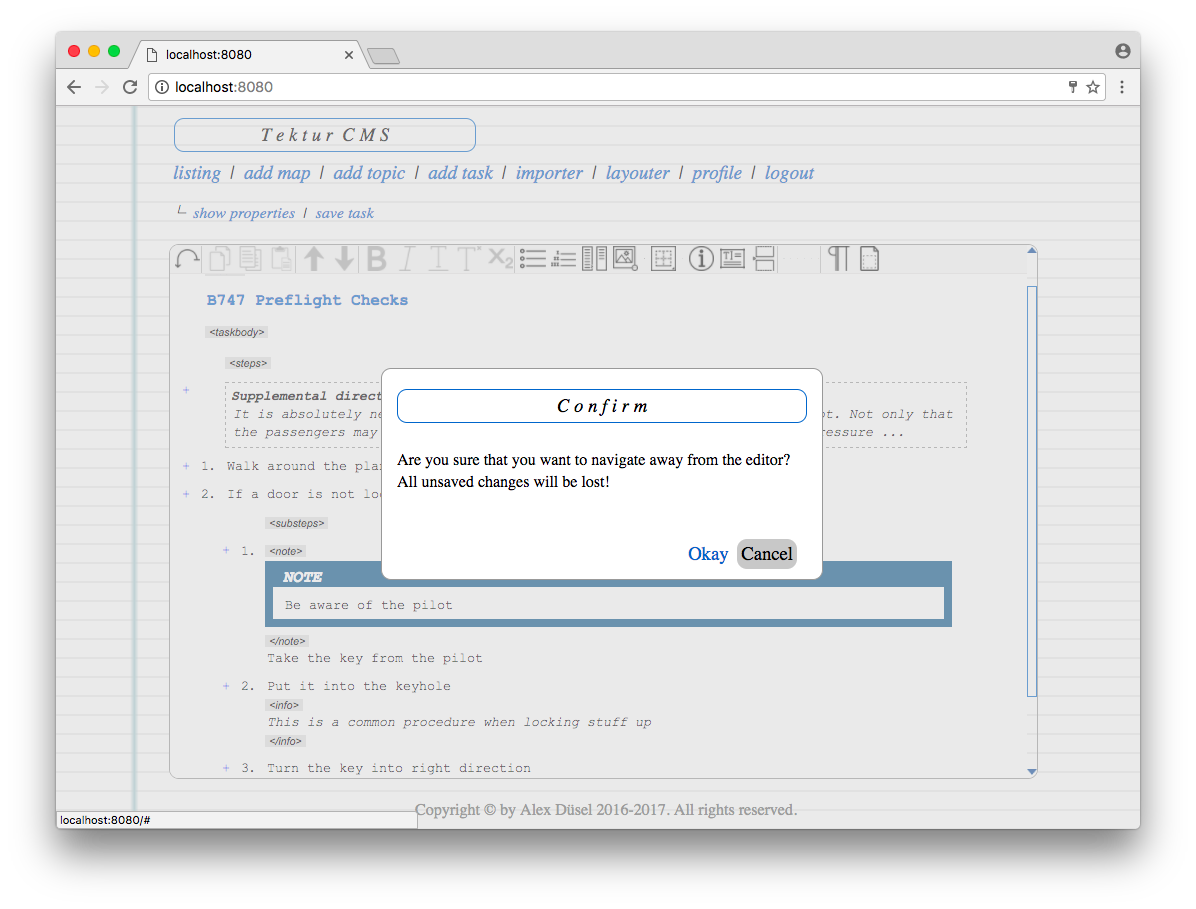
Confirm dialogs
Confirm dialogs are so important. Easy to overlook when designing the application. Maybe hard to implement later on. Here's a screenshot of the confirm dialog in the editor view.
November 6th, 2016
Topics Importer
I have been working on the Topics Importer. There will be two options when importing data:
- Fast bulk upload of data using a commandline tool that connects via HTTP.
- Individual users can upload single DITA topics or maps directly via the web interface.
For now, there is only the second option available. The corresponding popup dialog can be selected from the top menu.
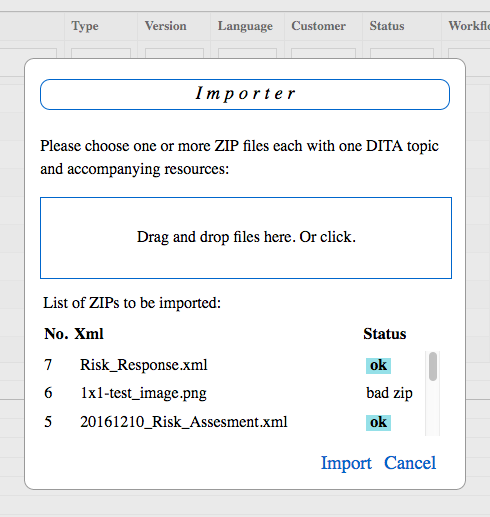
A ZIP to be imported must contain one XML file (the DITA topic) and may also contain multiple resource files. Zips can be uploaded by dragging them onto the marked area. (Implemented with the excellent Dropzone JS library)
Once uploaded the server will check for files corrupted or invalid. It will present the user with a list.
The user may correct the import by dragging files onto the upload area again or may cancel the upload. When clicking the import button the content of valid ZIPs is populated to the database.
Here's a sketch of this process:
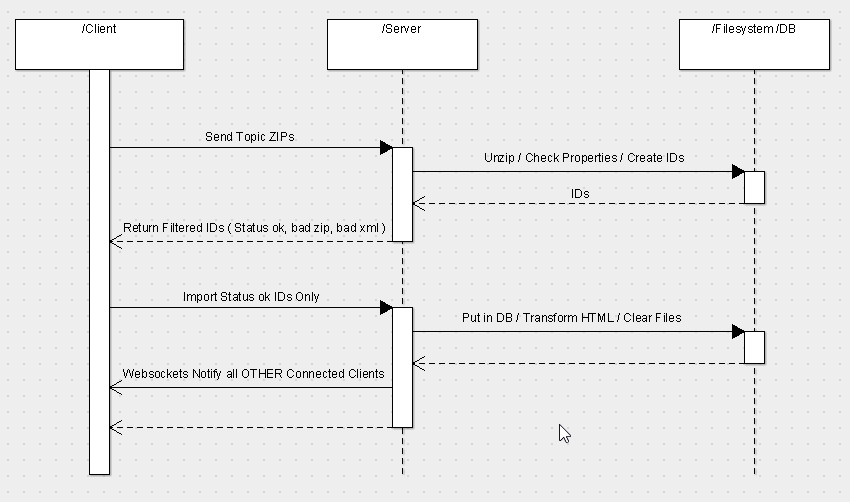
Note that all connected browsers will be updated with the changes in real-time using Websockets and NodeJS.
September 13th, 2016
More Mockups
Making mockups for popups...
There is definitely some need for more colors. How about "Raw Sienne" and "Aquamarine" for the highlighting stuff?


September 6th, 2016
Tektur Design
Since I liked the paper-and-pencil style of the ARC-Space game (see below) I will be reusing this design - together with the Courier New font family - for a simple and clean "Typewriter" look-and-feel. Just started with two dialogs:
September 5th, 2016
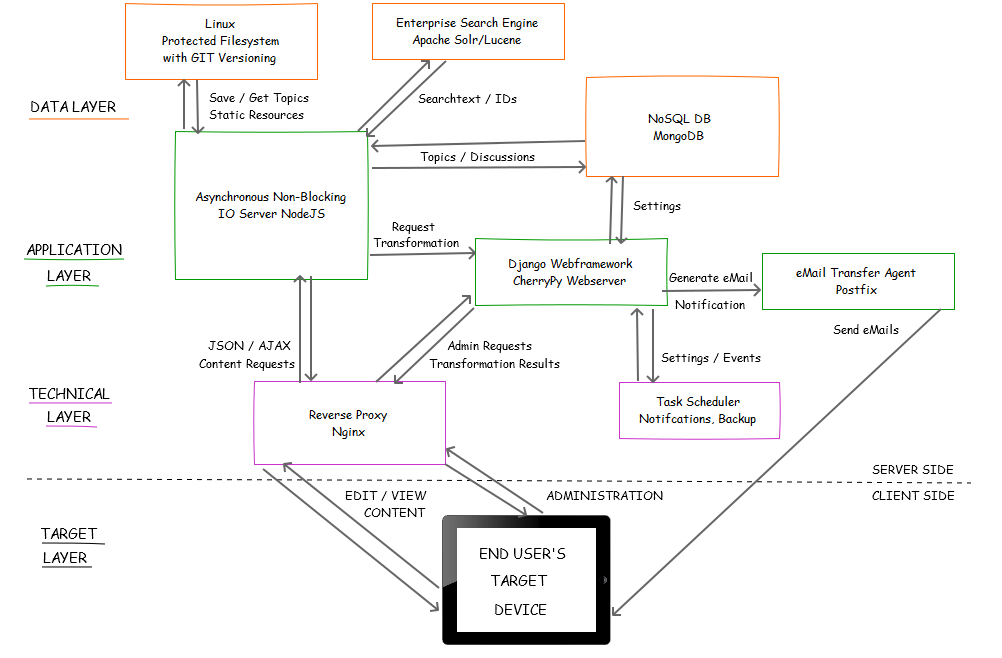
Tektur Tech Stack
Here's a first sketch of the architecture. Django will stay but only for the administrative backend and XSLT transformations (Django and Python evidentially do a good job in both areas).
August 16th, 2016
First JSON response
Basic concept: DITA topics are stored in a MongDB. Every topic is implemented by an item in a NoSQL collection. Every user maintains his own list of items that will be merged with other lists if users collaborate.
This is the JSON response for adding a test-topic:
{
"state": "success",
"data": {
"_id": "57b7c545bf08c4d40f8dd008",
"username": "alex",
"dateIssued": "2016-08-20T02:49:41.747Z",
"logged_in": true,
"test1": "10000",
"test2": "0",
"test3": "10",
"test4": "0",
"test5": "33",
"token": "aa32cd53-e762-4c4c-9da9-8ea6f16de1a7",
"usernames": [
"h",
"alex",
"sepp"
],
"application": {
"name": "Tektur",
"debugmode": true,
"tracker_id": "55a8cd3e700a9d6823742074",
"configuration": {}
},
"dateUpdated": "2016-08-20T02:50:20.981Z",
"topics": [
{
"element_id": "c399e3c3-4361-4b76-b6e9-52bd0de89fb2",
"title": "New Topic",
"body": "<p id=\"0cf33019-31db-4c06-a525-5261589e01c6\">New Para</p>"
},
{
"element_id": "7c466009-f742-4305-a6f3-f8248b999f2d",
"title": "New Topic",
"body": "<p id=\"73260170-c659-4813-a1f9-7f11c008589c\">New Para</p>"
},
{
"element_id": "b5e7f9ac-4bae-4ec8-8bcb-88b9a0a2e250",
"title": "New Topic",
"body": "<p id=\"2de8a6c1-3909-468d-8627-3f463d7d24dd\">New Para</p>"
}
]
},
"message": "Successfully added DITA test topic!"
}
I will add more useful data to this skeleton within the next few weeks... developing the system bottom-up.
August 13th, 2016
Tektur KickOff
During the last 3 years I have learnt a lot about what's important and what's not for a new kid in the XML CMS town. Requirements:
- Web-based
- Easy-to-use
- DITA data model
- Handle thousands of topics
- Integrated word-like editor
- Put focus on electronic formats (HTML5, ePub, etc)
- High-qualitiy print publication
- Flexible workflow system
- Configurable layout engine
- Real-time collaboration
- Software-as-a-service
- Fast single-page HTML5 GUI
More or less all of these points have already been evaluated. Now it's time to put all the pieces together.
Some parts of the UWE stack will stay whereas others will be dropped:
- Django Webframework will be replaced by NodeJS.
- MySQL database will be replaced by MongoDB, because of the tree-like nature of XML data in general and DITA topics more specifically.
- Search Engine will be Solr/Lucene.
- CKEditor will be dropped for a homebrew solution.
Actually I feel a bit sad, because there won't be any line of Python any more in the code. Python is still my favourite programming language, but obviously it's much better to build the stack upon one specific technology and not having a mixture of programming languages.
Since this will be my leisure time project, do not expect any production ready results before 2020.